云数据库概述
云计算是云数据库兴起的基础:
云计算的概念:通过整合、管理、调配分布在网络各处的计算资源,通过互联网以统一界面,同时向大量的用户提供服务。
云计算特点:按需服务,随时服务,通用型,高可靠性,极其廉价,超大规模,虚拟化,高扩展性。
云数据库的概念:
云数据库是部署和虚拟化在云计算环境中的数据库。云数据库是在云计算的大背景下发展起来的一种新兴的共享基础架构的方法,它极大地增强了数据库的存储能力,消除了人员、硬件、软件的重复配置,让软、硬件升级变得更加容易。云数据库具有高可扩展性、高可用性、采用多租形式和支持资源有效分发等特点。
云数据库的特性:
云数据库具有以下特性:
- 动态可扩展
- 高可用性
- 较低的使用代价
- 易用性
- 高性能
- 免维护
- 安全
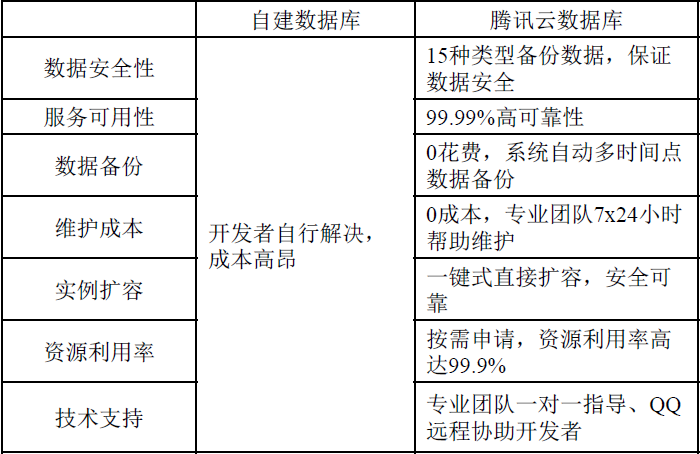
云数据库是个性化数据库存储需求的理想选择:
企业类型不同,对于存储的需求也千差万别,而云数据库可以很好地满足不同企业的个性化存储需求:
- 首先,云数据库可以满足大企业的海量数据存储需求。
- 其次,云数据库可以满足中小企业的低成本数据存储需求。
- 另外,云数据库可以满足企业动态变化的数据存储需求。
到底选择自建数据库还是选择云数据库,取决于企业自身的具体需求
- 对于一些大型企业,目前通常采用自建数据库
- 对于一些财力有限的中小企业而言,IT预算比较有限,云数据库这种前期零投入、后期免维护的数据库服务,可以很好满足它们的需求。
云数据库与其他数据库的关系:
从数据模型的角度来说,云数据库并非一种全新的数据库技术,而只是以服务的方式提供数据库功能。
云数据库并没有专属于自己的数据模型,云数据库所采用的数据模型可以是关系数据库所使用的关系模型(微软的SQL Azure云数据库、阿里云RDS都采用了关系模型),也可以是NoSQL数据库所使用的非关系模型(Amazon Dynamo云数据库采用的是“键/值”存储)。
同一个公司也可能提供采用不同数据模型的多种云数据库服务。
许多公司在开发云数据库时,后端数据库都是直接使用现有的各种关系数据库或NoSQL数据库产品。
云数据库产品
云数据库厂商的概述:
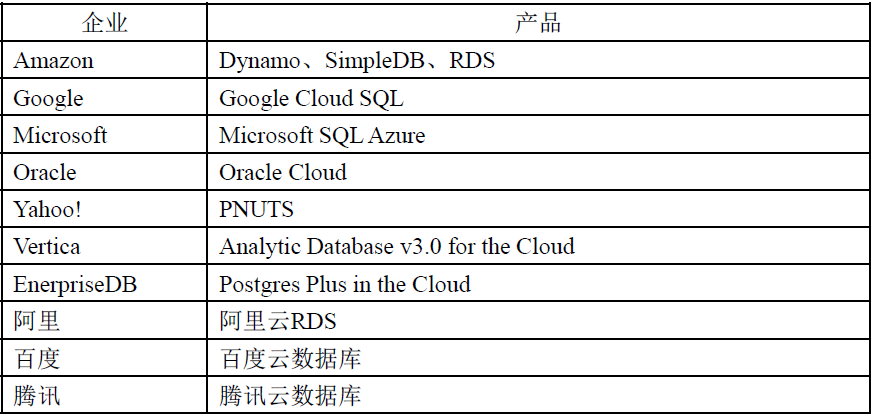
Amazon的云数据库产品:
Amazon是云数据库市场的先行者。Amazon除了提供著名的S3存储服务和EC2计算服务以外,还提供基于云的数据库服务:
- Amazon RDS:云中的关系数据库
- Amazon SimpleDB:云中的键值数据库
- Amazon DynamoDB:云中的NoSQL数据库
- Amazon Redshift:云中的数据仓库
- Amazon ElastiCache:云中的分布式内存缓存
Google的云数据库产品:
Google Cloud SQL是谷歌公司推出的基于MySQL的云数据库。
使用Cloud SQL,所有的事务都在云中,并由谷歌管理,用户不需要配置或者排查错误。
谷歌还提供导入或导出服务,方便用户将数据库带进或带出云。
谷歌使用用户非常熟悉的MySQL,带有JDBC支持(适用于基于Java的App Engine应用)和DB-API支持(适用于基于Python的App Engine应用)的传统MySQL数据库环境,因此,多数应用程序不需过多调试即可运行,数据格式对于大多数开发者和管理员来说也是非常熟悉的。
Google Cloud SQL还有一个好处就是与Google App Engine集成。
Microsoft的云数据库产品:
SQL Azure具有以下特性:
- 属于关系型数据库:支持使用TSQL(Transact Structured Query Language)来管理、创建和操作云数据库。
- 支持存储过程:它的数据类型、存储过程和传统的SQL Server具有很大的相似性,因此,应用可以在本地进行开发,然后部署到云平台上。
- 支持大量数据类型:包含了几乎所有典型的SQL Server 2008的数据类型。
- 支持云中的事务:支持局部事务,但是不支持分布式事务。
云数据库系统架构
UMP系统概述:
UMP(Unified MySQL Platform)系统是低成本和高性能的MySQL云数据库方案。总的来说,UMP系统架构设计遵循了以下原则:
- 保持单一的系统对外入口,并且为系统内部维护单一的资源池。
- 消除单点故障,保证服务的高可用性。
- 保证系统具有良好的可伸缩,能够动态地增加、删减计算与存储节点。
- 保证分配给用户的资源也是弹性可伸缩的,资源之间相互隔离,确保应用和数据安全。
UMP系统架构:
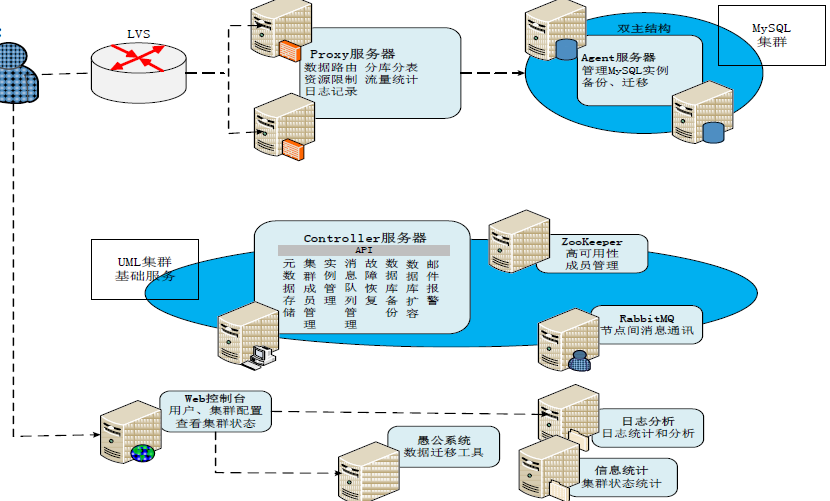
UMP系统中的角色包括:
(1)Controller服务器
- Controller服务器向UMP集群提供各种管理服务,实现集群成员管理、元数据存储、MySQL实例管理、故障恢复、备份、迁移、扩容等功能.
- Controller服务器上运行了一组Mnesia分布式数据库服务,其中存储了各种系统元数据,主要包括集群成员、用户的配置和状态信息,以及用户名到后端MySQL实例地址的映射关系(或称为“路由表”)等。
- 当其它服务器组件需要获取用户数据时,可以向Controller服务器发送请求获取数据。
- 为了避免单点故障,保证系统的高可用性,UMP系统中部署了多台Controller服务器,然后,由Zookeeper的分布式锁功能来帮助选出一个“总管”,负责各种系统任务的调度和监控。
(2)Proxy服务器
Proxy服务器向用户提供访问MySQL数据库的服务,它完全实现了MySQL协议,用户可以使用已有的MySQL客户端连接到Proxy服务器,Proxy服务器通过用户名获取到用户的认证信息、资源配额的限制(例如QPS、IOPS(I/O Per Second)、最大连接数等),以及后台MySQL实例的地址,然后,用户的SQL查询请求会被转发到相应的MySQL实例上。除了数据路由的基本功能外,Proxy服务器中还实现了很多重要的功能,主要包括屏蔽MySQL实例故障、读写分离、分库分表、资源隔离、记录用户访问日志等。
(3)Agent服务器
Agent服务器部署在运行MySQL进程的机器上,用来管理每台物理机上的MySQL实例,执行主从切换、创建、删除、备份、迁移等操作,同时,还负责收集和分析MySQL进程的统计信息、慢查询日志(Slow Query Log)和bin-log。
(4)Web控制台
Web控制台向用户提供系统管理界面。
(5)日志分析服务器
日志分析服务器存储和分析Proxy服务器传入的用户访问日志,并支持实时查询一段时间内的慢日志和统计报表。
(6)信息统计服务器
信息统计服务器定期将采集到的用户的连接数、QPS数值以及MySQL实例的进程状态用RRDtool进行统计,可以在 Web界面上可视化展示统计结果,也可以把统计结果作为今后实现弹性的资源分配和自动化的MySQL实例迁移的依据。
(7)愚公系统
愚公系统是一个全量复制结合bin-log分析进行增量复制的工具,可以实现在不停机的情况下动态扩容、缩容和迁移。
依赖的开源组件包括:
(1)Mnesia
- Mnesia是一个分布式数据库管理系统.
- Mnesia支持事务,支持透明的数据分片,利用两阶段锁实现分布式事务,可以线性扩展到至少50个节点。
- Mnesia的数据库模式(schema)可在运行时动态重配置,表能被迁移或复制到多个节点来改进容错性。
- Mnesia的这些特性,使其在开发云数据库时被用来提供分布式数据库服务。
(2)LVS
- LVS(Linux Virtual Server)即Linux虚拟服务器,是一个虚拟的服务器集群系统。
- UMP系统借助于LVS来实现集群内部的负载均衡。
- LVS集群采用IP负载均衡技术和基于内容请求分发技术。
- 调度器是LVS集群系统的唯一入口点,调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。
- 整个服务器集群的结构对客户是透明的,而且无需修改客户端和服务器端的程序。
(3)RabbitMQ
- RabbitMQ是一个工业级的消息队列产品(功能类似于IBM公司的消息队列产品IBM Websphere MQ),作为消息传输中间件来使用,可以实现可靠的消息传送。
- UMP集群中各个节点之间的通信,不需要建立专门的连接,都是通过读写队列消息来实现的。
(4)ZooKeeper
Zookeeper是高效和可靠的协同工作系统,提供分布式锁之类的基本服务(比如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等),用于构建分布式应用,减轻分布式应用程序所承担的协调任务.
在UMP系统中,Zookeeper主要发挥三个作用:
- 作为全局的配置服务器
- 提供分布式锁(选出一个集群的“总管”)
- 监控所有MySQL实例
UMP系统功能:
UMP系统是构建在一个大的集群之上的,通过多个组件的协同作业,整个系统实现了对用户透明的各种功能:
容灾、读写分离、分库分表、资源管理、资源调度、资源隔离、数据安全。
容灾:
为了实现容灾,UMP系统会为每个用户创建两个MySQL实例,一个是主库,一个是从库主库和从库的状态是由Zookeeper负责维护的。
主从切换过程如下:
- Zookeeper探测到主库故障,通知Controller服务器。
- Controller服务器启动主从切换时,会修改“路由表”,即用户名到后端MySQL实例地址的映射关系。
- 把主库标记为不可用。
- 借助于消息中间件RabbitMQ通知所有Proxy服务器修改用户名到后端MySQL实例地址的映射关系。
- 全部过程对用户透明。
宕机后的主库在进行恢复处理后需要再次上线,过程如下:
- 在主库恢复时,会把从库的更新复制给自己。
- 当主库的数据库状态快要达到和从库一致的状态时,Controller服务器就会命令从库停止更新,进入不可写状态,禁止用户写入数据。
- 等到主库更新到和从库完全一致的状态时,Controller服务器就会发起主从切换操作,并在路由表中把主库标记为可用状态。
- 通知Proxy服务器把写操作切回主库上,用户写操作可以继续执行,之后再把从库修改为可写状态。
读写分离:
充分利用主从库实现用户读写操作的分离,实现负载均衡。
UMP系统实现了对于用户透明的读写分离功能,当整个功能被开启时,负责向用户提供访问MySQL数据库服务的Proxy服务器,就会对用户发起的SQL语句进行解析,如果属于写操作,就直接发送到主库,如果是读操作,就会被均衡地发送到主库和从库上执行。
分库分表:
UMP支持对用户透明的分库分表(shard / horizontal partition) 当采用分库分表时,系统处理用户查询的过程如下:
- 首先,Proxy服务器解析用户SQL语句,提取出重写和分发SQL语句所需要的信息。
- 其次,对SQL语句进行重写,得到多个针对相应MySQL实例的子语句,然后把子语句分发到对应的MySQL实例上执行。
- 最后,接收来自各个MySQL实例的SQL语句执行结果,合并得到最终结果。
资源管理:
UMP系统采用资源池机制来管理数据库服务器上的CPU、内存、磁盘等计算资源,所有的计算资源都放在资源池内进行统一分配,资源池是为MySQL实例分配资源的基本单位。
整个集群中的所有服务器会根据其机型、所在机房等因素被划分多个资源池,每台服务器会被加入到相应的资源池中。
对于每个具体MySQL实例,管理员会根据应用部署在哪些机房、需要哪些计算资源等因素,为该MySQL实例具体指定主库和从库所在的资源池,然后,系统的实例管理服务会本着负载均衡的原则,从资源池中选择负载较轻的服务器来创建MySQL实例。
资源调度:
UMP系统中有三种规格的用户,分别是数据量和流量比较小的用户、中等规模用户以及需要分库分表的用户。
- 多个小规模用户可以共享同一个MySQL实例
- 对于中等规模的用户,每个用户独占一个MySQL实例
- 对于分库分表的用户,会占有多个独立的MySQL实例
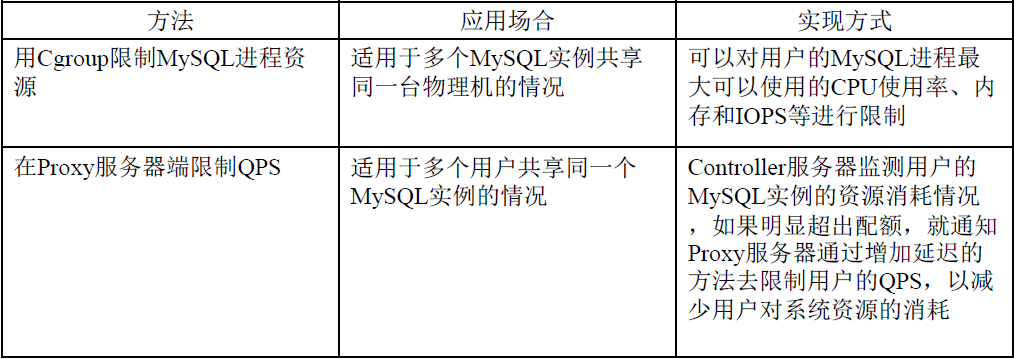
资源隔离:
UMP采用的两种资源隔离方式:
数据安全:
UMP系统设计了多种机制来保证数据安全:
- SSL数据库连接:SSL(Secure Sockets Layer)是为网络通信提供安全及数据完整性的一种安全协议,它在传输层对网络连接进行加密。Proxy服务器实现了完整的MySQL客户端/服务器协议,可以与客户端之间建立SSL数据库连接。
- 数据访问IP白名单:可以把允许访问云数据库的IP地址放入“白名单”,只有白名单内的IP地址才能访问,其他IP地址的访问都会被拒绝,从而进一步保证账户安全。
- 记录用户操作日志:用户的所有操作记录都会被记录到日志分析服务器,通过检查用户操作记录,可以发现隐藏的安全漏洞。
- SQL拦截:Proxy服务器可以根据要求拦截多种类型的SQL语句,比如全表扫描语句“select *”。
Amazon AWS(Amazon Web Services)和云数据库
Amazon和云计算的渊源:
- 2016年3月14日,亚马逊网络服务(AWS)十岁了。
- Amazon Web Services业务相当于紧随其后的4大竞争对手的总和。
- 亚马逊在全球拥有12个区域性数据中心。
- Amazon Web Services提供的多个亚马逊数据库都在与甲骨文(Oracle)激烈竞争,其中Amazon RDS有10万多个活跃用户。
- 亚马逊数据库Aurora,是Amazon Web Services历史上增长最快的服务。
亚马逊的云服务提供了多达几十种服务,涵盖了IaaS、PaaS、SaaS这三层。
Amazon AWS:
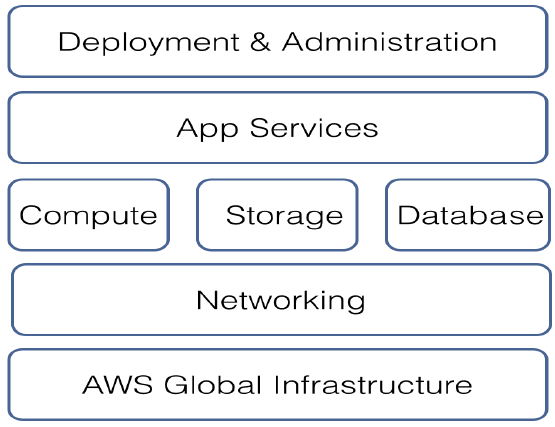
(1)AWS Global Infrastructure(AWS全局基础设施)
在全局基础设施中有3个很重要的概念。
- 第一个是Region(区域),每个Region是相互独立的,自成一套云服务体系,分布在全球各地。目前全球有10个Region(比如 北京)。
- 第二个是Availability Zone(可用区),每个Region又由数个可用区组成,每个可用区可以看做一个数据中心,相互之间通过光纤连接。
- 第三个是Edge Locations(边缘节点)。全球目前有50多个边缘节点,是一个内容分发网络(CDN,Content Distrubtion Network),可以降低内容分发的延迟,保证终端用户获取资源的速度。
(2)Network(网络):
AWS提供的网络服务主要有:
- Direct Connect:支持企业自身的数据中心直接与AWS的数据中心直连,充分利用企业现有的资源。
- VPN Connection:通过VPN连接AWS,保证数据的安全性。
- Virtual Private Cloud: 私有云,从AWS云资源中分一块给你使用,进一步提高安全性。
- Route 53:亚马逊提供的高可用的可伸缩的云域名解析系统。Amazon Route 53 高效地将用户请求连接到 AWS 中运行的基础设施,例如 Amazon EC2 实例、Elastic Load Balancing 负载均衡器或 Amazon S3 存储桶。
(3)Computer(计算):
亚马逊的计算核心,包括了众多的服务:
- EC2: Elastic Compute Cloud,亚马逊的虚拟机,支持Windows和Linux的多个版本,支持API创建和销毁,有多种型号可供选择,按需使用。并且有自动扩展功能(5分钟即可新建一个虚拟机),有效解决应用程序性能问题。
- ELB: Elastic Load Balancing, 亚马逊提供的负载均衡器,可以和EC2无缝配合使用,横跨多个可用区,可以自动检查实例的健康状况,自动剔除有问题的实例,保证应用程序的可靠性。
- Glacier:主要用于较少使用的存储存档文件和备份文件,价格便宜量又足,安全性高。
(4)DateBase(数据库):
亚马逊提供关系型数据库和NoSQL数据库,以及一些cache等数据库服务:
- SimpleDB:基于云的键 / 值数据存储服务。
- DynamoDB: DynamoDB是亚马逊自主研发的No SQL数据库,性能高,容错性强,支持分布式。
- RDS:Relational Database Service,关系型数据库服务。支持MySQL,SQL Server和Oracle等数据库。
- Amazon ElastiCache: 数据库缓存服务。
(5)Application Server(应用程序服务):
- Cloud Search: 一个弹性的搜索引擎,可用于企业级搜索
- Amazon SQS: 队列服务,存储和分发消息
- Simple Workflow:一个工作流框架
- CloudFront:世界范围的内容分发网络(CDN)
- EMR: Elastic MapReduce,一个Hadoop框架架的实例,可用于大数据处理。
(6)Deployment & Admin(部署和管理):
- Elastic BeanStalk: 一键式创建各种开发环境和运行时。
- CloudFormation:采用JSON格式的模板文件来创建和管理一系列亚马逊云资源。
- OpsWorks: OpsWorks允许用户将应用程序的部署模块化,可以实现对数据库、运行时、服务器软件等自动化设置和安装。
- IAM: Identity & Access Management,认证和访问管理服务。用户使用云服务最担心的事情之一就是安全问题。亚马逊通过IAM提供了立体化的安全策略,保证用户在云上的资源绝对的安全
总体而言,Amazon AWS的产品分为几个部分:
计算类
- 弹性计算云EC2:EC2提供了云中的虚拟机。
- 弹性MapReduce:将Hadoop MapReduce搬到云环境中,大量EC2实例动态地成为执行大规模MapReduce计算任务的工作机。
存储类
- 弹性块存储EBS
- 简单消息存储SQS
- Blob对象存储S3
- NoSQL型数据库:SimpleDB和DynamoDB
- 关系数据库RDS
工具支持
- AWS支持多种开发语言,提供Java、Rupy、Python、PHP、Windows &.NET 以及Android和iOS的工具集。
- 工具集中包含各种语言的SDK,程序自动部署以及各种管理工具。
- AWS通过CloudWatch系统提供丰富的监控功能。
微软云数据库SQL Azure
SQL Azure简介:
SQL Azure是微软的云关系型数据库,后端存储又称为“云SQL Server”。
构建在SQL Server之上,通过分布式技术提升传统关系数据库的可扩展性和容错能力。
云SQL Server数据模型:
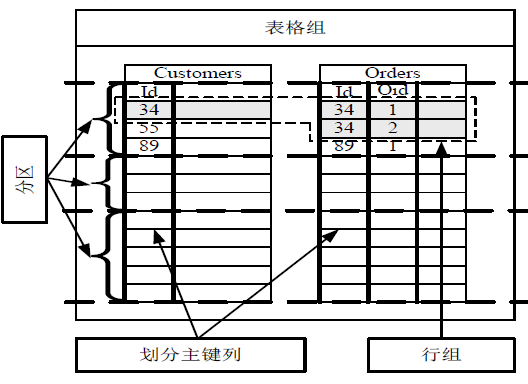
1.逻辑模型:
- 一个逻辑数据库称为一个表格组
- 表格组中所有划分主键相同的行集合称为行组(row group)
- 只支持同一个行组内的事务,同一个行组的数据逻辑上会分布到一台服务器,以此规避分布式事务
- 通过主备复制将数据复制到多个副本,保证高可用性
2.物理模型:
- 在物理层面,每个有主键的表格组根据划分主键列有序地分成多个数据分区。每个行组属于唯一分区。
- 分区是SQL Azure复制、迁移、负载均衡的基本单位。每个分区包含多个副本(默认为3),每个副本存储在一台物理的SQL Server上。
- SQL Azure保证每个分区的多个副本分布到不同的故障域。每个分区有一个副本为主副本(Primary),其他副本为从副本(Secondary)。主副本处理所有的查询、更新事务,并以操作日志的形式,将事务同步到从副本,从副本接收主副本发送的事务日志并应用到本地数据库。
体系架构:
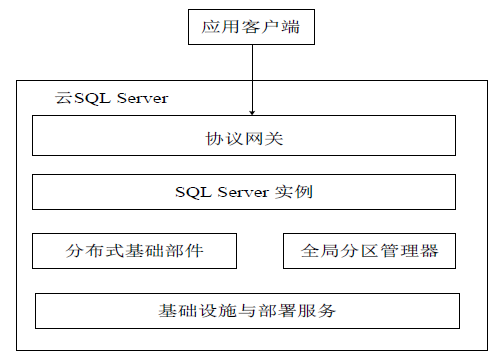
SQL Azure分为四个主要部分: SQL Server实例、全局分区管理器、协议网关、分布式基础部件。
- 每个SQL Server实例是一个运行着SQLServer的物理进程。每个物理数据库包含多个子数据库,它们之间相互隔离。子数据库是一个分区,包含用户的数据以及schema信息.
- 全局分区管理器维护分区映射表信息.
- 协议网关负责将用户的数据库连接请求转发到相应的主分区上.
- 分布式基础部件(Fabric)用于维护机器上下线状态,检测服务器故障并为集群中的各种角色执行选取主节点操作.
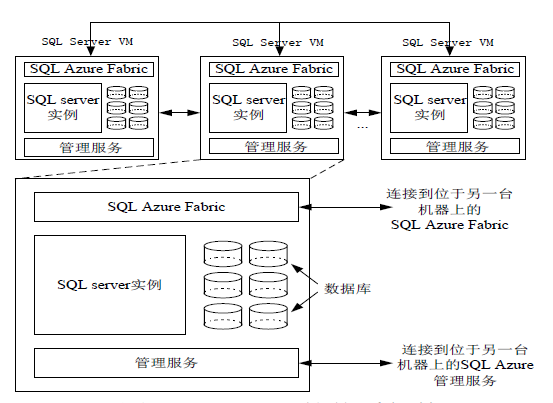
- SQL Azure的体系架构中包含了一个虚拟机簇,可以根据工作负载的变化,动态增加或减少虚拟机的数量。
- 每台虚拟机SQL Server VM(virtualmachine)安装了SQL Server 数据库管理系统,以关系模型存储数据。
- 通常,一个数据库会被散存储到3~5台SQL Server VM中。
阿里云RDS
阿里云RDS简介:
RDS是阿里云提供的关系型数据库服务,它将直接运行于物理服务器上的数据库实例租给用户,是专业管理的、高可靠的云端数据库服务。
RDS由专业数据库管理团队维护,还可以为用户提供数据备份、数据恢复、扩展升级等管理功能,相对于用户自建数据库而言,RDS具有专业、高可靠、高性能、灵活易用等优点,能够帮助用户解决费时费力的数据库管理任务,让用户将更多的时间聚焦在核心业务上。
RDS具有安全稳定、数据可靠、自动备份、管理透明、性能卓越,灵活扩容等优点,可以提供专业的数据库管理平台、专业的数据库优化建议以及完善的监控体系。
RDS中的概念:
RDS实例,是用户购买RDS服务的基本单位。在实例中:
- 可以创建多个数据库
- 可以使用常见的数据库客户端连接、管理及使用数据
- 可以通过RDS管理控制台或OPEN API来创建、修改和删除数据库
RDS数据库,是用户在一个实例下创建的逻辑单元
- 一个实例可以创建多个数据库,在实例内数据库命名唯一,所有数据库都会共享该实例下的资源,如CPU、内存、磁盘容量等
- RDS不支持使用标准的SQL语句或客户端工具创建数据库,必须使用OPEN API或RDS管理控制台进行操作
地域指的是用户所购买的RDS实例的服务器所处的地理位置。
RDS目前支持杭州、青岛、北京、深圳和香港五个地域,服务品质完全相同。用户可以在购买RDS实例时指定地域,购买实例后暂不支持更改。
RDS可用区是指在同一地域下,电力、网络隔离的物理区域,可用区之间内网互通,可用区内网络延时更小,不同可用区之间故障隔离。
RDS可用区又分为单可用区和多可用区
- 单可用区是指RDS实例的主备节点位于相同的可用区,它可以有效控制云产品间的网络延迟
- 多可用区是指RDS实例的主备节点位于不同的可用区,当主节点所在可用区出现故障(如机房断电等),RDS进行主备切换后,会切换到备节点所在的可用区继续提供服务。多可用区的RDS轻松实现了同城容灾
磁盘容量是用户购买RDS实例时,所选择购买的磁盘大小
实例所占用的磁盘容量,除了存储表格数据外,还有实例正常运行所需要的空间,如系统数据库、数据库回滚日志、重做日志、索引等。
RDS连接数,是应用程序可以同时连接到RDS实例的连接数量
- 任意连接到RDS实例的连接均计算在内,与应用程序或者网站能够支持的最大用户数无关
- 用户在购买RDS
以上内容为听华为大数据培训课程和大学MOOC上厦门大学 林子雨的《大数据技术原理与应用》课程而整理的笔记。
大数据技术原理与应用: https://www.icourse163.org/course/XMU-1002335004

