什么是shell:
shell就是系统跟计算机硬件交互时使用的中间介质,它只是系统的一个工具。实际上,在shell和计算机硬件之间还有一层东西那就是系统内核了。用户直接面对的不是计算机硬件而是shell,用户把指令告诉shell,然后shell再传输给系统内核,接着内核再去支配计算机硬件去执行各种操作。
linux发布版本(Redhat/CentOS)系统默认安装的shell叫做bash,即Bourne Again Shell,它是sh(Bourne Shell)的增强版本。Bourn Shell 是最早行起来的一个shell,创始人叫Steven Bourne,为了纪念他所以叫做Bourn Shell,检称sh。bash的特点如下:
(1)记录历史命令:
Linux预设可以记录1000条历史命令。这些命令保存在用户的家目录中的.bash_history文件中。有一点需要您知道的是,只有当用户正常退出当前shell时,在当前shell中运行的命令才会保存至.bash_history文件中。
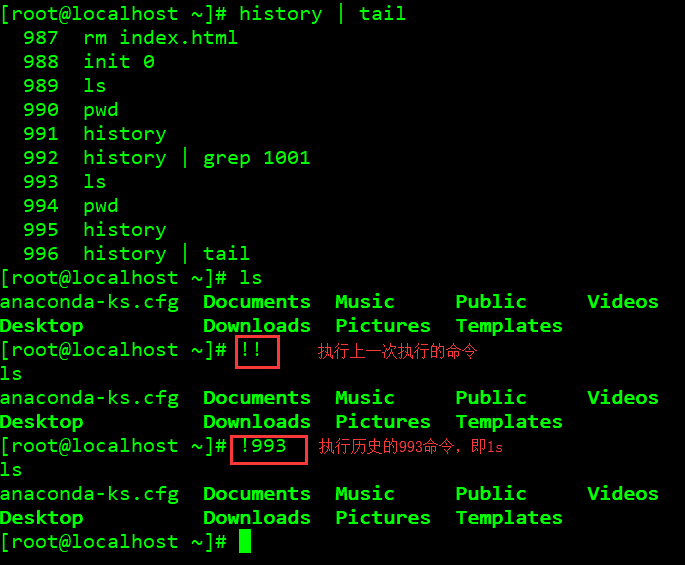
与命令历史有关的有一个有意思的字符那就是 ‘!’ 了。常用的有这么几个应用:
- !! 连续两个 ‘!’, 表示执行上一条指令;
- !n 这里的n是数字,表示执行命令历史中第n条指令,例如
!989表示执行命令历史中第989个命令;history命令如果未改动过环境变量,默认可以把最近1000条命令历史打印出来。
(2)指令和文件名补全:
tab键可以补全一个命令或者路径名, 文件名。连续按两次tab键,系统则会把所有的指令或者文件名都列出来。
(3)别名:
alias(别名),这也是bash所特有的功能之一。可以通过alias把一个常用的并且很长的指令别名一个简洁易记的指令。如果不想用了,还可以用unalias解除别名功能。直接敲alias会看到目前系统预设的alias.
1 | [root@localhost ~]# alias |
也可以自定义想要指令别名。alias的语法:alias 命令别名=‘具体的命令’使用 unalias 命令别名 就可以把设置的别名给解除了。
1 | [root@localhost ~]# alias test='ls' |
(4)通配符:
在bash下,可以使用 * 来匹配零个或多个字符,而用 ? 匹配一个字符。
(5)输入输出重定向:
输入重定向用于改变命令的输入,输出重定向用于改变命令的输出。输出重定向更为常用,它经常用于将命令的结果输入到文件中,而不是屏幕上。输入重定向的命令是<,输出重定向的命令是>,另外还有错误重定向2>,以及追加重定向>>。
(6)管道:
管道符:‘|’,就是把前面命令的运行结果作为后面命令的输入。
(7)作业控制:
当运行一个进程时,可以使它暂停(按Ctrl+z),然后使用fg命令恢复它,利用bg命令使他到后台运行,也可以使它终止(按Ctrl+c)。
当在后台运行多个任务时,可以同时jobs 命令来查看在后台运行的进程。然后可以通过fg 进程编号 命令来继续恢复该进程。
当需要杀死某个进程时,可先通过ps 命令来查看正在运行的进程。然后用kill 进程号 来杀死进程。
变量:
环境变量PATH,这个环境变量就是shell预设的一个变量,通常shell预设的变量都是大写的。变量,说简单点就是使用一个较简单的字符串来替代某些具有特殊意义的设定以及数据。就拿PATH来讲,这个PATH就代替了所有常用命令的绝对路径的设定。因为有了PATH这个变量,所以我们运行某个命令时不再去输入全局路径,直接敲命令名即可。可以使用echo命令显示变量的值。
1 | [root@localhost ~]# echo $PATH |
可以使用env 命令来列出系统预设的全部变量。不过登录的用户不一样这些环境变量的值也不一样。当前显示的就是root这个账户的环境变量了。
1 | [root@localhost ~]# env |
在常见的环境变量中:
- PATH:决定了shell将到哪些目录中寻找命令或程序。
- HOME:当前用户主目录。
- HISTSIZE:历史记录数。
- LOGNAME:当前用户的登录名。
- HOSTNAME:指主机的名称。
- SHELL:当前用户shell类型。
- LANG:语言相关的环境变量,多语言可以修改此环境变量。
- MAIL:当前用户的邮件存放目录。
- PWD:当前目录。
env命令显示的变量只是环境变量,系统预设的变量其实还有很多,可以使用set命令把系统预设的全部变量都显示出来。
set不仅可以显示系统预设的变量,也可以连同用户自定义的变量显示出来。
1 | [root@localhost ~]# myname=Cao #自定义变量 |
自定义的变量只能在当前shell中生效。如果使用base命令再打开一个shell,自定义的shell就不存在了。如果想要自定义的shell一直生效。有两种情况:
如果想让系统内所有用户登录后都可以使用该变量:
需要在“/etc/profile” 文件最末行加入
export 自定义变量然后运行source /etc/profile就可以生效了。只想让当前用户使用该变量:
需要在用户主目录下的
.bashrc
文件最后一行加入export 自定义变量然后运行source .bashrc就可以生效了。source命令的作用是,将目前设定的配置刷新,即不用注销再登录也能生效。
自定义变量的规则:
设定变量的格式为 “a=b”, 其中a为变量名,b为变量的内容,等号两边不能有空格;
变量名只能由英、数字以及下划线组成,而且不能以数字开头;
当变量内容带有特殊字符(如空格)时,需要加上单引号;
有一种情况,需要注意,就是变量内容中本身带有单引号,这就需要用到双引号了。
如果变量内容中需要用到其他命令运行结果则可以使用反引号;
变量内容可以累加其他变量的内容,需要加双引号;
如果不小心把双引号加错为单引号,将得不到想要的结果。
单引号和双引号的区别:用双引号时不会取消掉里面出现的特殊字符的本身作用(这里的$),而使用单引号则里面的特殊字符全部失去它本身的作用。
bash命令: 如果在当前shell中运行bash指令后,则会进入一个新的shell,这个shell就是原来shell的子shell了,可以pstree指令来查看。
pstree 这个指令会把linux系统中所有进程通过树形结构打印出来。在父shell中设定一个变量后,进入子shell后该变量是不会生效的,如果想让这个变量在子shell中生效则要用到export指令。
export其实就是声明一下这个变量的意思,让该shell的子shell也知道变量。如果export后面不加任何变量名,则它会声明所有的变量。
如果想取消某个变量:通过命令unset 变量名 去掉即可。
系统环境变量与个人环境变量的配置文件:
/etc/profile :这个文件预设了几个重要的变量,例如PATH, USER, LOGNAME, MAIL, INPUTRC, HOSTNAME, HISTSIZE, umask等等。
/etc/bashrc :这个文件主要预设umask以及PS1。PS1就是用户平时的提示符。
1 | [root@localhost ~]# echo $PS1 |
\u就是用户,\h主机名,\W则是当前目录,\$就是那个 ‘#’ 了,如果是普通用户则显示为 ‘$’.
除了两个系统级别的配置文件外,每个用户的主目录下还有几个这样的隐藏文件:
- .bash_profile :定义了用户的个人化路径与环境变量的文件名称。每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次。
- .bashrc :该文件包含专用于用户的shell的bash信息,当登录时以及每次打开新的shell时,该该文件被读取。例如可以将用户自定义的alias或者自定义变量写到这个文件中。
- .bash_history :记录命令历史用的。
- .bash_logout :当退出shell时,会执行该文件。可以把一些清理的工作放到这个文件中。
Linux shell中的特殊符号:
常见符号的意思:
*代表零个或多个任意字符。?只代表一个任意的字符 ,不管是数字还是字母,只要是一个都能匹配出来。#这个符号在linux中表示注释说明的意思,即#后面的内容linux忽略掉。\脱意字符,将后面的特殊符号(例如” * ” )还原为普通字符。|管道符,前面多次出现过,它的作用在于将符号前面命令的结果丢给符号后面的命令。这里提到的后面的命令,并不是所有的命令都可以的,一般针对文档操作的命令比较常用,例如cat, less, head, tail, grep, cut, sort, wc, uniq, tee, tr, split, sed, awk等等。
$除了用于变量前面的标识符外,还有一个妙用,就是和 ‘!’ 结合起来使用。!$表示上条命令中最后一个变量(总之就是上条命令中最后出现的那个东西)例如上边命令最后是tesb.txt那么在当前命令下输入!$则代表test.txt.1
2
3
4
5[root@localhost ~]# ls test.txt
test.txt
[root@localhost ~]# ls !$
ls test.txt
test.txt;: 分号。平时我们都是在一行中敲一个命令,然后回车就运行了,那么想在一行中运行两个或两个以上的命令如何呢?则需要在命令之间加一个 ”;” 了。1
2
3
4
5[root@localhost ~]# head -n 3/etc/passwd; head test.txt
root:x:0:0:usr:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
44
55~: 用户的家目录,如果是root则是 /root ,普通用户则是 /home/username 。&: 如果想把一条命令放到后台执行的话,则需要加上这个符号。通常用于命令运行时间非常长的情况。>, >>, 2>, 2>> :重定向符号> 以及>> 分别表示取代和追加的意思,然后还有两个符号就是这里的2> 和 2>> 分别表示错误重定向和错误追加重定向,当我们运行一个命令报错时,报错信息会输出到当前的屏幕,如果想重定向到一个文本里,则要用2>或者2>> 。
[ ]:中括号,中间为字符组合,代表中间字符中的任意一个。&& 与 ||: 分号,用于多条命令间的分隔符。还有两个可以用于多条命令中间的特殊符号,那就是 “&&” 和 “||” .- command1 ; command2
- command1 && command2
- command1 || command2
使用 ”;” 时,不管command1是否执行成功都会执行command2;
使用 “&&” 时,只有command1执行成功后,command2才会执行,否则command2不执行;
使用 “||” 时,command1执行成功后command2 不执行,否则去执行command2,总之command1和command2总有一条命令会执行。
常用的一些命令:
命令cut :用来截取某一个字段。
语法: cut -d '分隔字符' [-cf] n 这里的n是数字。
- -d(delimiter):分界符,后面跟分隔字符,分隔字符要用单引号括起来。
- -c(characters):后面接第几个字符。
- -f*(fields):后面接的是第几个区块。
用法示例:
1 | [root@localhost ~]# cat /etc/passwd | head -n 5 |
在上面的使用中,-d后面跟分割符,这里使用冒号作为分隔符。-f:后面跟截取第几段,1就是截取一段,2就是第二段。-f和1之间的空格可有可无。
-c 后面跟的是第几个字符,后面的数字是1-n,也可以是一个区间,如1-5,也可以是多个数:n1,n2等。
命令sort:用作排序。
语法: sort [-t 分隔符] [-kn1,n2] [-nru] 这里的n1 < n2
常用的选项:
- t(field-separator):分隔符:作用和cut的-d是一个意思。
- -n(numeric-sort):使用纯数字排序。
- -r(reverse):反向排序。
- -u(unique):去重复。
- -kn1,n2:由n1区间排序到n2区间。可以只写-kn1,即对n1字段排序。
sort命令使用示例:
1 | [root@localhost ~]# head -n5 /etc/passwd | sort |
如果sort不加任何选项,则从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
1 | [root@localhost ~]# head -n5 /etc/passwd | sort -t : -k3 -n |
-t 后面跟分隔符,-k后面跟数字,表示对第几个区域的字符串排序,-n 则表示使用纯数字排序。上面这条命令:以:为分割符,对第三个区域的数据进行排序。
1 | [root@localhost ~]# head -n5 /etc/passwd | sort -t: -k3,5 -r |
-k3,5 表示从第3到第5区域间的字符串排序,-r表示反向排序。
命令wc:用于统计文档的行数、字符数、词数。
用法:wc 选项 文件 。
常用的选项有:
-l (lines):统计行数
-m (chars):统计字符数
-w (words):统计词数
wc 不跟任何选项,直接跟文档,则会把行数、词数、字符数依次输出。
1 | [root@localhost ~]# wc /etc/passwd |
命令uniq:去重复的行。
语法:uniq 参数 文件名
常用的选项:
-c:统计重复的行数,并把行数写在前面。
使用uniq 的前提是需要先给文件排序,否则不管用。
使用示例:
1 | [root@localhost ~]# cat test.txt |
命令tee:标准输入复制到每个指定文件,并显示到标准输出。
用法:tee [选项]... [文件]...
-a(append) : 内容追加到给定的文件而非覆盖。
后跟文件名,类似与重定向 “>”, 但是比重定向多了一个功能,在把文件写入后面所跟的文件中的同时,还显示在屏幕上。
tee 常用语管道符 “|” 后。
1 | [root@localhost ~]# echo "44" | tee test.txt |
命令tr:从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出。
用法:tr [选项]... SET1 [SET2]
常用的选项有两个:
- -d(delete) :删除某个字符,-d 后面跟要删除的字符
- -s(squeeze-repeats) :把重复的字符去掉.
- 最常用的就是把小写变大写: tr ‘[a-z]’ ‘[A-Z]’
SET 是一组字符串,一般都可按照字面含义理解。解析序列如下:
\NNN 八进制值为NNN 的字符(1 至3 个数位)
\ 反斜杠
\a 终端鸣响
\b 退格
\f 换页
\n 换行
\r 回车
\t 水平制表符
\v 垂直制表符
字符1-字符2 从字符1 到字符2 的升序递增过程中经历的所有字符
[字符] 在SET2 中适用,指定字符会被连续复制直到吻合设置1 的长度
[字符次数] 对字符执行指定次数的复制,若次数以 0 开头则被视为八进制数
[:alnum:] 所有的字母和数字
[:alpha:] 所有的字母
[:blank:] 所有呈水平排列的空白字符
[:cntrl:] 所有的控制字符
[:digit:] 所有的数字
[:graph:] 所有的可打印字符,不包括空格
[:lower:] 所有的小写字母
[:print:] 所有的可打印字符,包括空格
[:punct:] 所有的标点字符
[:space:] 所有呈水平或垂直排列的空白字符
[:upper:] 所有的大写字母
[:xdigit:] 所有的十六进制数
[=字符=] 所有和指定字符相等的字符
用法示例:
1 | [root@localhost ~]# head -n5 /etc/passwd | tr '[a-z]' '[A-Z]' |
替换、删除以及去重复都是针对一个字符来讲的,有一定局限性。如果是针对一个字符串就不再管用了。
命令splist:切割文档。
用法:split [选项]... [输入 [前缀]]
常用选项:
-b :依据大小来分割文档,单位为byte。
-l(lines) :依据行数来分割文档。
如果split不指定目标文件名,则会以xaa xab… 这样的文件名来存取切割后的文件。当然我们也可以指定目标文件名。
用法示例:
1 | [root@localhost ~]# split test.txt |

