Spark概述
Spark简介:
Spark最初由美国加州伯克利大学(UCBerkeley)的AMP实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。
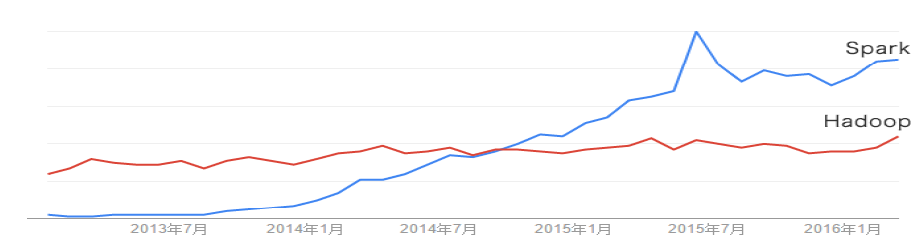
2013年Spark加入Apache孵化器项目后发展迅猛,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一(Hadoop、Spark、Storm)。
Spark在2014年打破了Hadoop保持的基准排序纪录
- Spark/206个节点/23分钟/100TB数据
- Hadoop/2000个节点/72分钟/100TB数据
- Spark用十分之一的计算资源,获得了比Hadoop快3倍的速度。
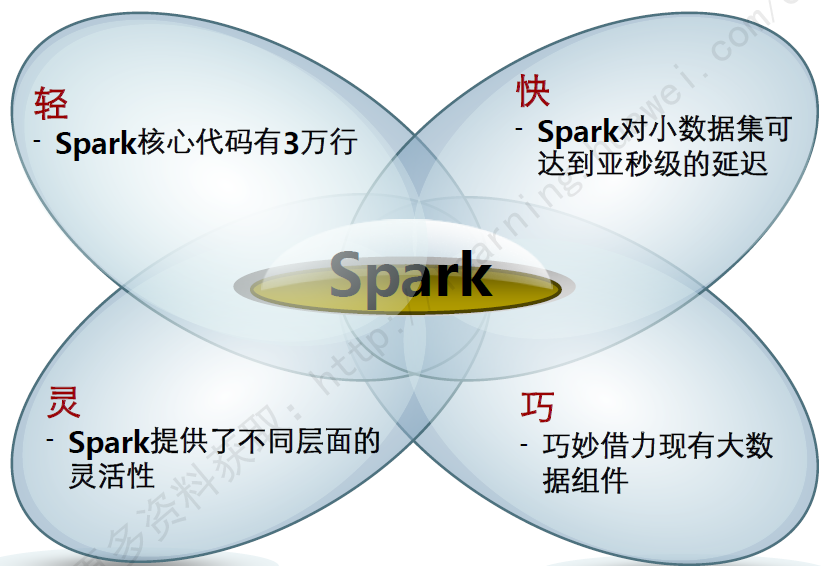
Spark具有如下几个主要特点:
- 运行速度快:使用DAG执行引擎以支持循环数据流与内存计算。
- 容易使用:支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程。
- 通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件。
- 运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
Spark如今已吸引了国内外各大公司的注意,如腾讯、淘宝、百度、亚马逊等公司均不同程度地使用了Spark来构建大数据分析应用,并应用到实际的生产环境中。
Spark是什么?
- Spark是一个基于内存的分布式批处理引擎。
- 由AMP LAB贡献到Apache社区的开源项目,是AMP大数据栈的基础组件。
- Spark是一站式解决方案,集批处理、实时流计算、交互式查询、图计算与机器学习与一体。
Spark做什么?
- 数据处理(Data Processing):可以用来快速处理数据,兼具容错性和可扩展性。
- 迭代计算(Iterrative Computation):支持迭代计算,有效应对多步数据处理逻辑。
- 数据挖掘(Data Mining):在还海量数据的基础上进程复杂的挖掘分析,可支持各种数据挖掘和机器学习算法。
Spark适用场景:
- 数据处理,ETL(抽取、转换、加载)
- 机器学习。如:可用于自动判断淘宝买家的评论是好评还是差评。
- 交互式分析:可用于查询Hive数据仓库。
- 特别使用与迭代计算,数据重复利用场景。
- 流计算:流处理可用于页面点击浏览分析,推荐系统,舆情分析等实时业务。
需要反复操作的次数越多,所需读取的数据量越大,收益越大。
Scala简介:
Scala是一门现代的多范式编程语言,运行于Java平台(JVM,Java 虚拟机),并兼容现有的Java程序。
Scala的特性:
- Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统。
- Scala语法简洁,能提供优雅的API
Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中。
Scala是Spark的主要编程语言,但Spark还支持Java、Python、R作为编程语言 Scala的优势是提供了REPL(Read-Eval-Print Loop,交互式解释器),提高程序开发效率。
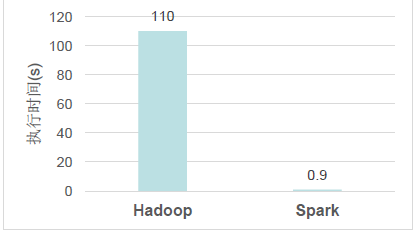
Spark与Hadoop的对比:
对比Hadoop:
- 性能上提升高于100倍。
- Spark的中间数据存放在内存中,对于迭代运算的效率更高,进行批处理时更高效。
- 更低的延时。
- Spark提供更多的数据操作类型,编程模型比Hadoop更灵活,开发效率更高。
- 更高的容错能力(血统机制)。
Hadoop存在如下一些缺点:
- 表达能力有限
- 磁盘IO开销大
- 延迟高
- 任务之间的衔接涉及IO开销
- 在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务
Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题。
相比于Hadoop MapReduce,Spark主要具有如下优点:
- Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活。
- Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高 Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制。
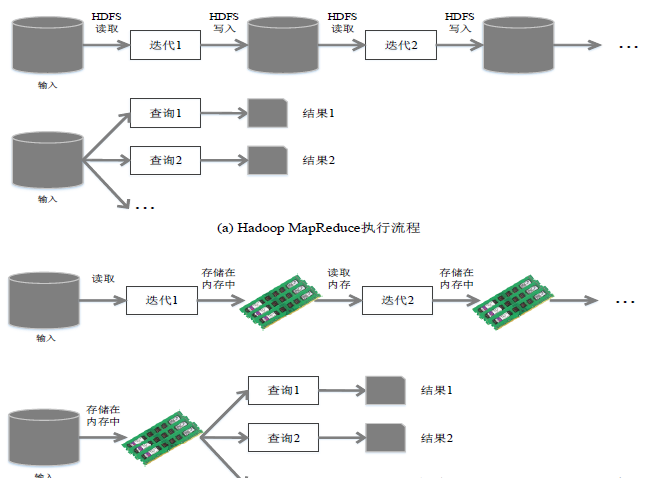
使用Hadoop进行迭代计算非常耗资源。Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据。
Spark生态系统
##Spark生态系统的原因:
在实际应用中,大数据处理主要包括以下三个类型:
- 复杂的批量数据处理:通常时间跨度在数十分钟到数小时之间。
- 基于历史数据的交互式查询:通常时间跨度在数十秒到数分钟之间。
- 基于实时数据流的数据处理:通常时间跨度在数百毫秒到数秒之间。
当同时存在以上三种场景时,就需要同时部署三种不同的软件
- 比如: MapReduce / Impala / Storm
这样做难免会带来一些问题:
- 不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换。
- 不同的软件需要不同的开发和维护团队,带来了较高的使用成本。
- 比较难以对同一个集群中的各个系统进行统一的资源协调和分配。
Spark设计的理念:
Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系统。
既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等。
Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。
因此,Spark所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和流数据处理。
Spark生态系统:

Spark生态系统已经成为伯克利数据分析软件栈BDAS(Berkeley Data Analytics Stack)的重要组成部分。
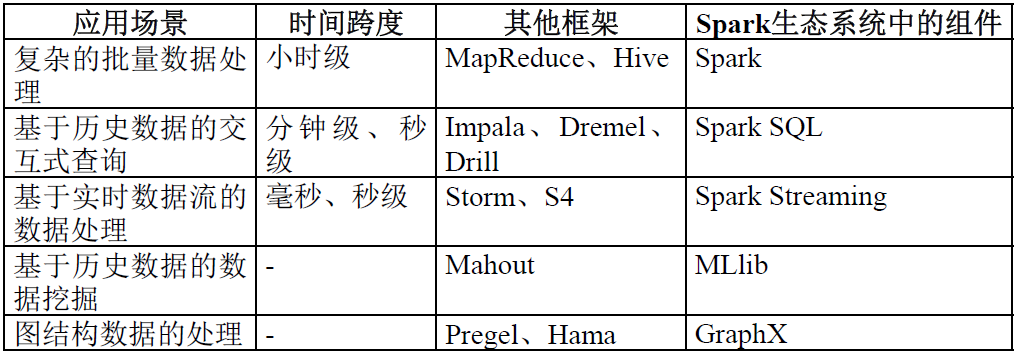
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX 等组件。
Spark生态系统组件的应用场景:
Spark运行架构
基本概念:
- RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
- DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系。
- Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task。
- Application:用户编写的Spark应用程序。
- Task:运行在Executor上的工作单元。
- Job:一个Job包含多个RDD及作用于相应RDD上的各种操作。
- Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集。
Spark架构设计:
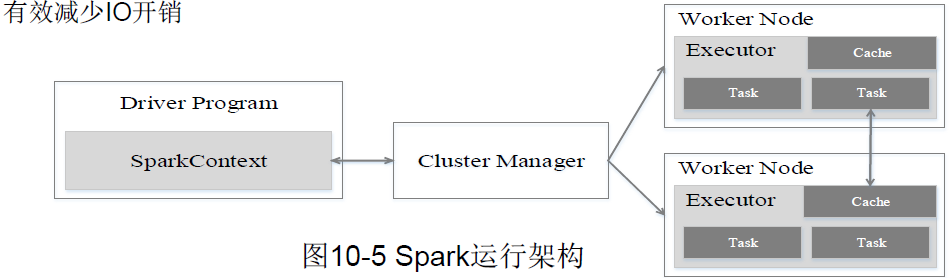
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。
资源管理器可以自带或Mesos或YARN。(在华为FusionInsight中只能用YARN。)
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:
- 一是利用多线程来执行具体的任务,减少任务的启动开销。
- 二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销。
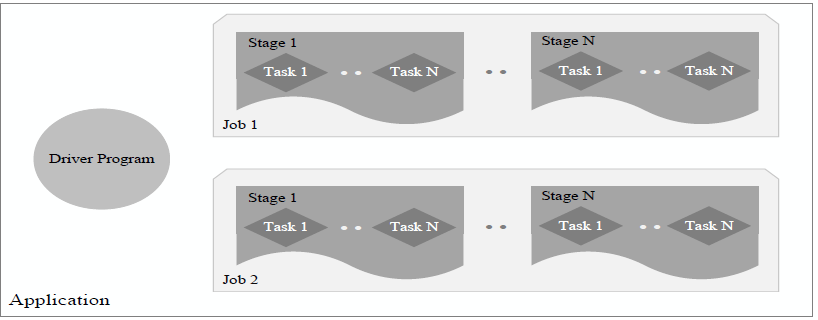
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成.
当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其他数据库中。
Spark运行基本流程:
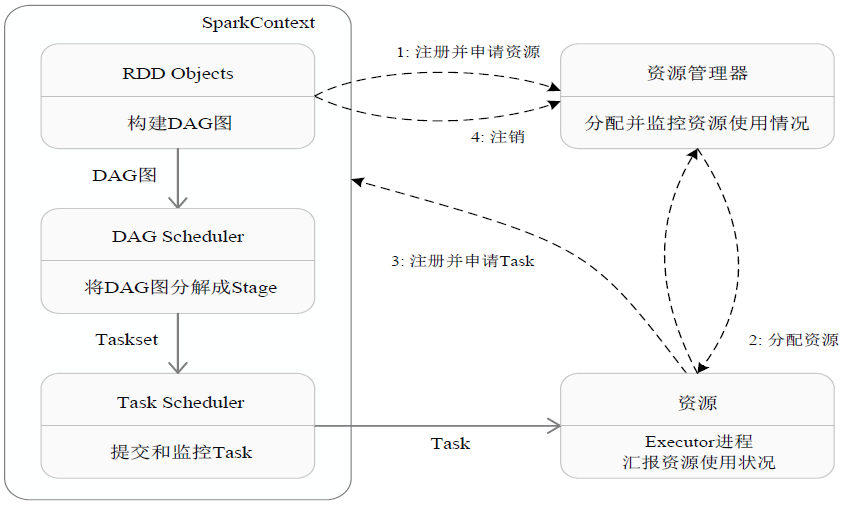
Spark运行基本流程如下:
- 首先为应用构建起基本的运行环境,即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控。
- 资源管理器为Executor分配资源,并启动Executor进程。
- SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,并提供应用程序代码。
- Task在Executor上运行,把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源。
总体而言,Spark运行架构具有以下特点:
- 每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task。
- Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可。
- Task采用了数据本地性和推测执行等优化机制。
Spark on Yarn的运行流程:
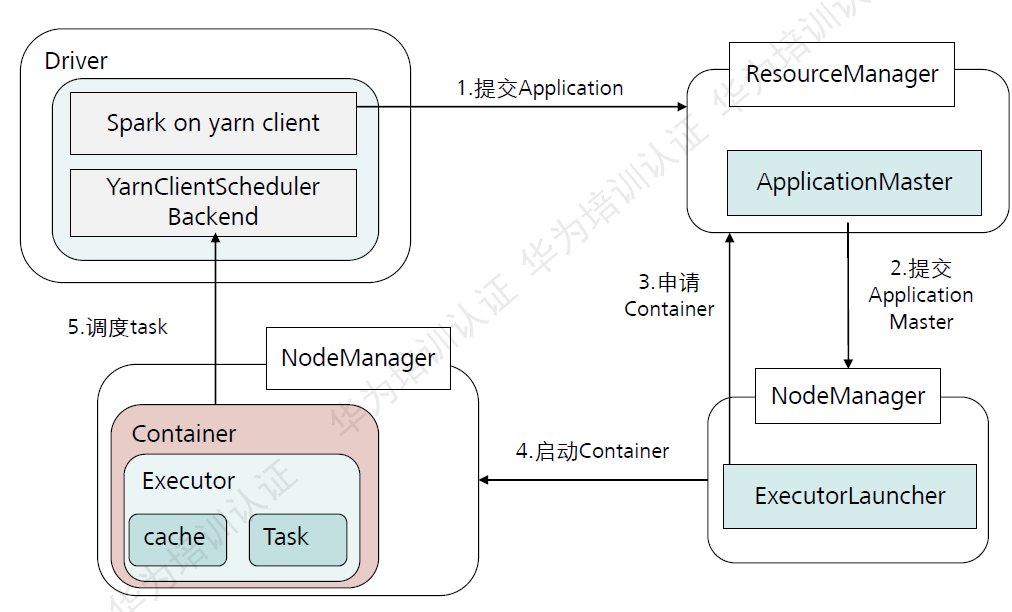
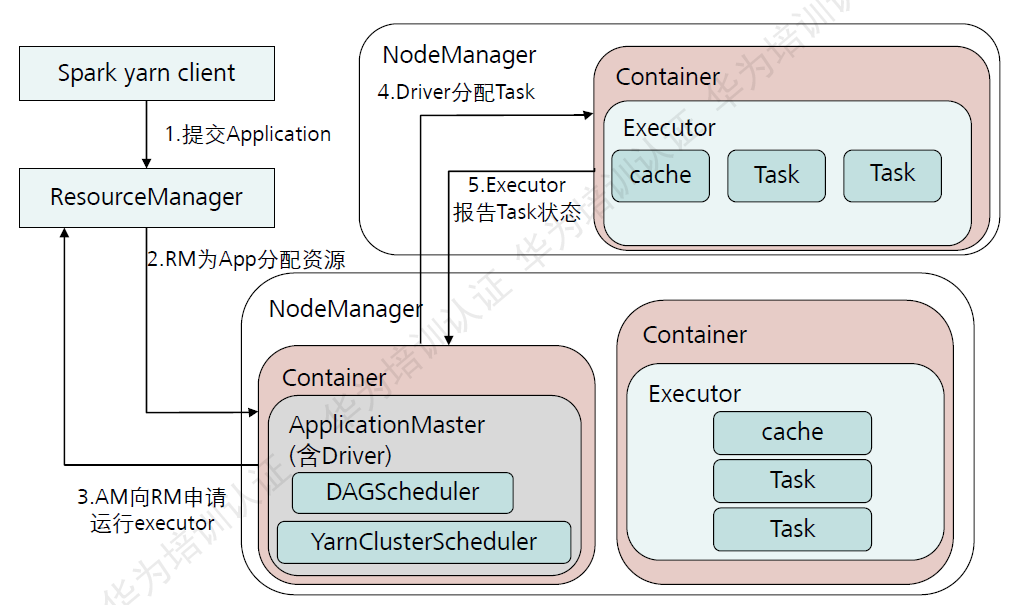
Yarn-client和Yarn-cluster的区别:
- Yarn-client和Yarn-cluster主要区别是Application Master进程的区别。
- Yarn-client适合测试,Yarn-cluster适合生成。
- Yarn-client任务提交节点宕机,整个任务失败。Yarn-cluster不会。
RDD运行原理
设计背景:
许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具,共同之处是,不同计算阶段之间会重用中间结果。
目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。
RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储。
RDD概念:
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和group by)而创建得到新的RDD。
RDD提供了一组丰富的操作以支持常见的数据运算,分为“动作”(Action)和“转换”(Transformation)两种类型。
RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改(不适合网页爬虫)。
表面上RDD的功能很受限、不够强大,实际上RDD已经被实践证明可以高效地表达许多框架的编程模型(比如MapReduce、SQL、Pregel)。
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。
RDD典型的执行过程如下:
- RDD读入外部数据源进行创建。
- RDD经过系列的转换(Transformation)操作,每一次都会产生不同的RDD,供给下一个转换操作使用。
- 最后一个RDD经过“动作”操作进行转换,并输出到外部数据源。
这一系列处理称为一个Lineage(血缘关系),即DAG拓扑排序的结果。
优点:惰性调用、管道化、避免同步等待、不需要保存中间结果、每次操作变得简单。

RDD特性:
Spark采用RDD以后能够实现高效计算的原因主要在于:
(1)高效的容错性
- 现有容错机制:数据复制或者记录日志。
- RDD:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同节点之间并行、只记录粗粒度的操作。
(2)中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免了不必要的读写磁盘开销 。
(3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化。
RDD之间的依赖关系:
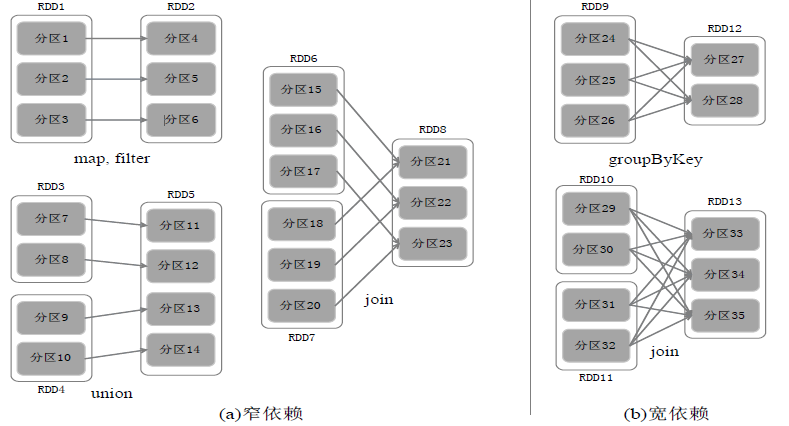
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区.
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。
Stage的划分:
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage,具体划分方法是:
- 在DAG中进行反向解析,遇到宽依赖就断开
- 遇到窄依赖就把当前的RDD加入到Stage中
- 将窄依赖尽量划分在同一个Stage中,可以实现流水线计算
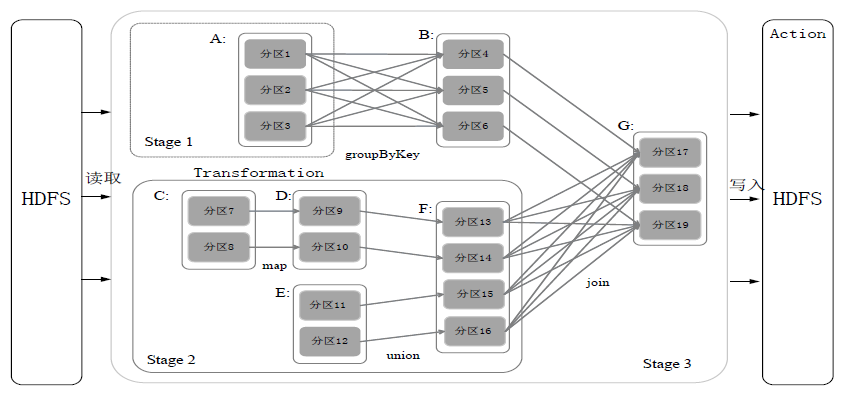
如上图,被分成三个Stage,在Stage2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作。
流水线操作实例:
分区7通过map操作生成的分区9,可以不用等待分区8到分区10这个map操作的计算结束,而是继续进行union操作,得到分区13,这样流水线执行大大提高了计算的效率。
Stage的类型包括两种:ShuffleMapStage和ResultStage,具体如下:
(1)ShuffleMapStage:不是最终的Stage,在它之后还有其他Stage,所以,它的输出一定需要经过Shuffle过程,并作为后续Stage的输入;这种Stage是以Shuffle为输出边界,其输入边界可以是从外部获取数据,也可以是另一个ShuffleMapStage的输出,其输出可以是另一个Stage的开始;在一个Job里可能有该类型的Stage,也可能没有该类型Stage;
(2)ResultStage:最终的Stage,没有输出,而是直接产生结果或存储。这种Stage是直接输出结果,其输入边界可以是从外部获取数据,也可以是另一个ShuffleMapStage的输出。在一个Job里必定有该类型Stage。因此,一个Job含有一个或多个Stage,其中至少含有一个ResultStage。
RDD运行的过程:
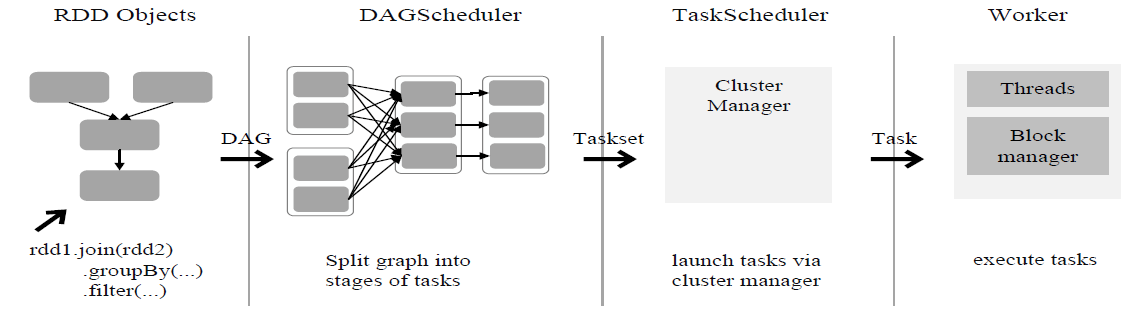
通过上述对RDD概念、依赖关系和Stage划分的介绍,结合之前介绍的Spark运行基本流程,再总结一下RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。
RDD的算子:
Transformation:
- Transformation是通过转换从一个或多个RDD生成新的RDD,该操作时Lazy的,当调用action算子,才发起job。
- 典型算子:map、flatMap、filter、reduceByKey。
Action:
- 当代码调用该类型算子时,立即启动job。
- 典型算子:take、count、savaAsTextFile等。
Spark SQL
从Shark说起:
Shark即Hive on Spark,为了实现与Hive兼容,Shark在HiveQL方面重用了Hive中HiveQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MapReduce作业替换成了Spark作业,通过Hive的HiveQL解析,把HiveQL翻译成Spark上的RDD操作。
Shark的设计导致了两个问题:
- 一是执行计划优化完全依赖于Hive,不方便添加新的优化策略;
- 二是因为Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支。
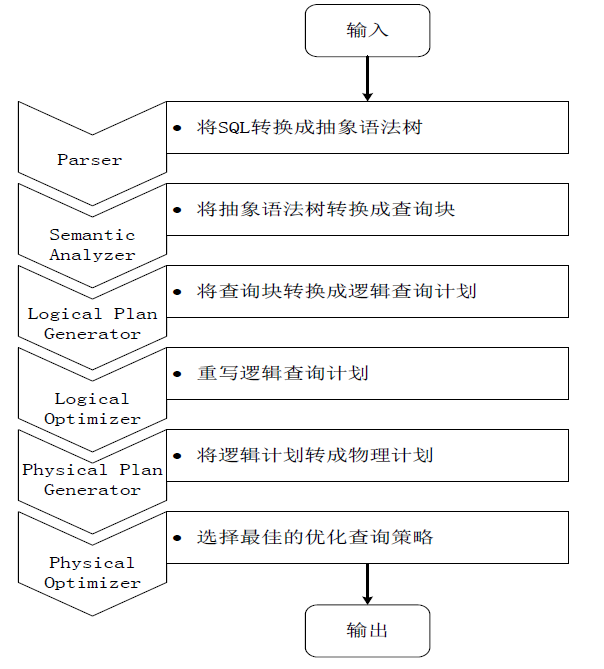
Spark SQL设计:
Spark SQL是Spark中用于结构化数据处理的模块。在Spark应用中,可以无缝的使用SQL语句亦或是DataFrame APi对结构化数据进程查询。
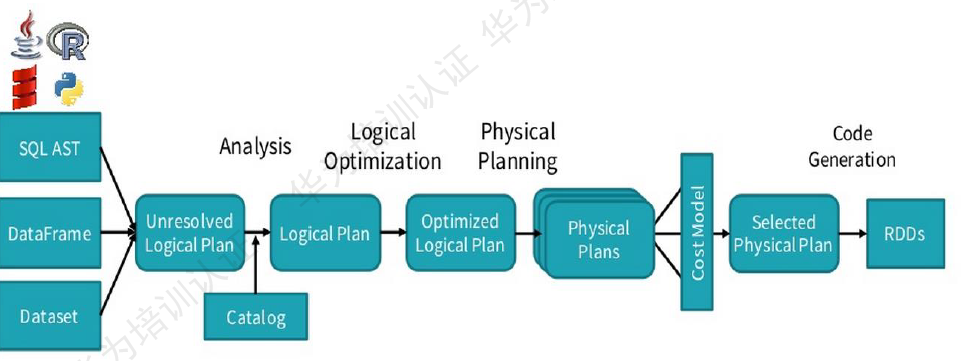
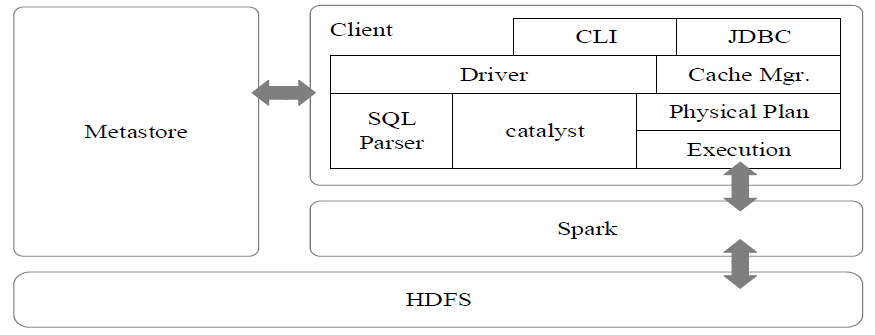
Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。
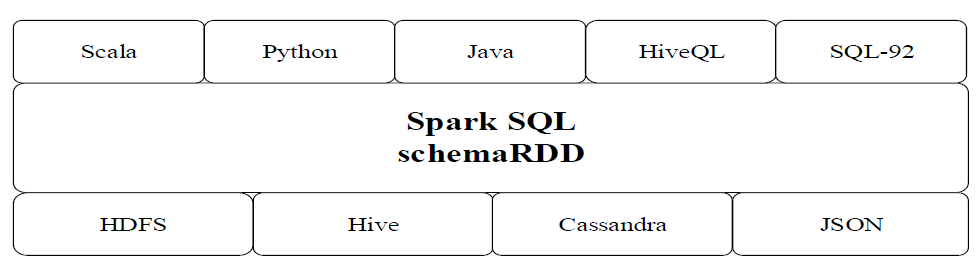
Spark SQL增加了SchemaRDD(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以是Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。
Spark SQL目前支持Scala、Java、Python三种语言,支持SQL-92规范。
Dataset简介:
DataSet是一个由特定域的对象组成的强类型集合,可通过功能或关系操作并行转换其中的对象。
DataSet以Catalyst逻辑执行计划表示,并且数据以编码的二进制形式存储,不需要反序列化就可以执行sort、filter、shuffle等操作。
DataSet是“懒惰的”,只在执行cation操作时触发计算。当执行action操作时,Spark用查询优化程序来优化逻辑计划,并生成一个高效的并行分布式的物理计划。
DataFrame介绍:
DateFrame:指定列名称的DataSet。DataFream是Dataset[Row]的特例。
RDD、DataFrame与Dataset:
RDD:
- 优点:类型安全,面向对象。
- 缺点:序列化和反序列化的性能开销大;GC的性能开销,频繁的创建和销毁对象,势必会增加GC。
DataFrame:
- 优点:自带scheme信息,降低序列化反序列化开销。
- 缺点:不是面向对象的。编译器不安全。
Dataset的特点:
- 快:大多数场景下,性能优于RDD;Encoders(编译器)优于Kryo或者Java序列号;避免了不必要的格式转换。
- 类型安全:类似于RDD,函数尽可能编译时安全。
- 和DataFrame,RDD互相转换。
Dataset具有RDD和DataFrame的有点,又避免它们的缺点。
Spark SQL vs Hive:
区别:
- Spark SQL的执行引擎为Spark core,HIve默认执行引擎为MapReduce。
- Spark SQL的执行速度是Hive的10-100倍。
- Spark SQL不支持buckets,Hive支持。
联系:
- Spark SQL依赖于Hive的元数据。
- Spark SQL兼容绝大部分Hive的语法和函数。
- Spark SQL可以使用HIve的自定义函数。
Spark Structured Streaming
Structured Streaming概述:
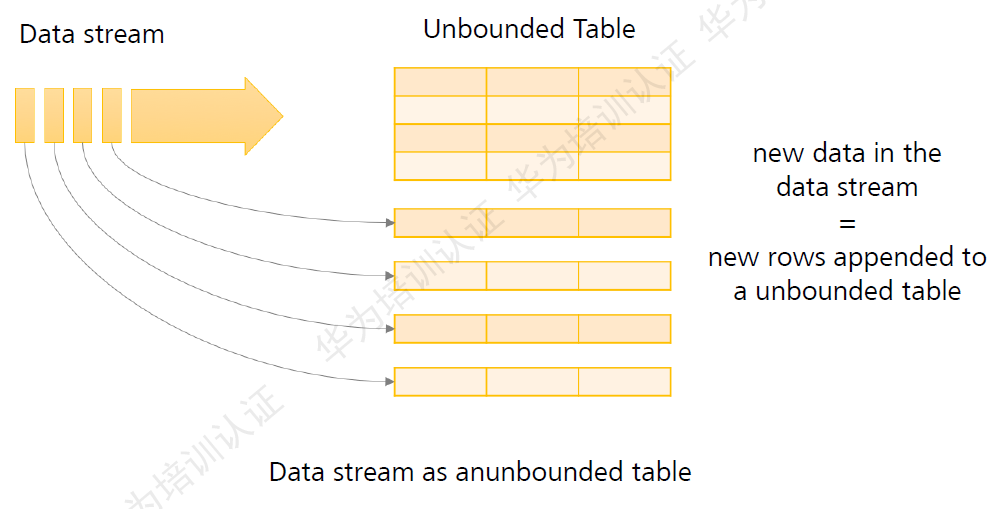
Structured Streaming是构建在Spark SQL引擎上的流式数据处理引擎。可以像使用静态RDD数据那样编写流式计算过程。当流数据连续不断的产生时,SPark SQL将会增量的、持续不断的处理这些数据,并将结果更新到结果集中。如下图:
Structured Streaming计算模型:
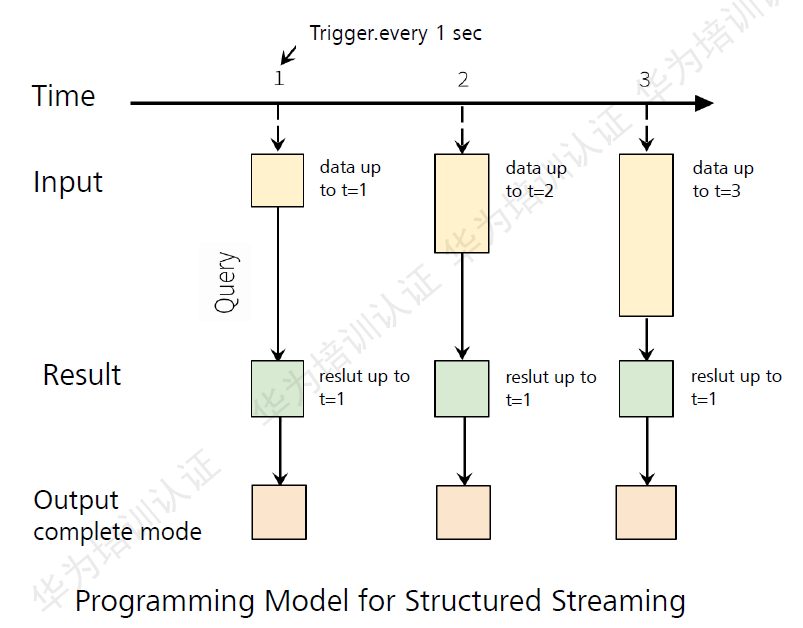
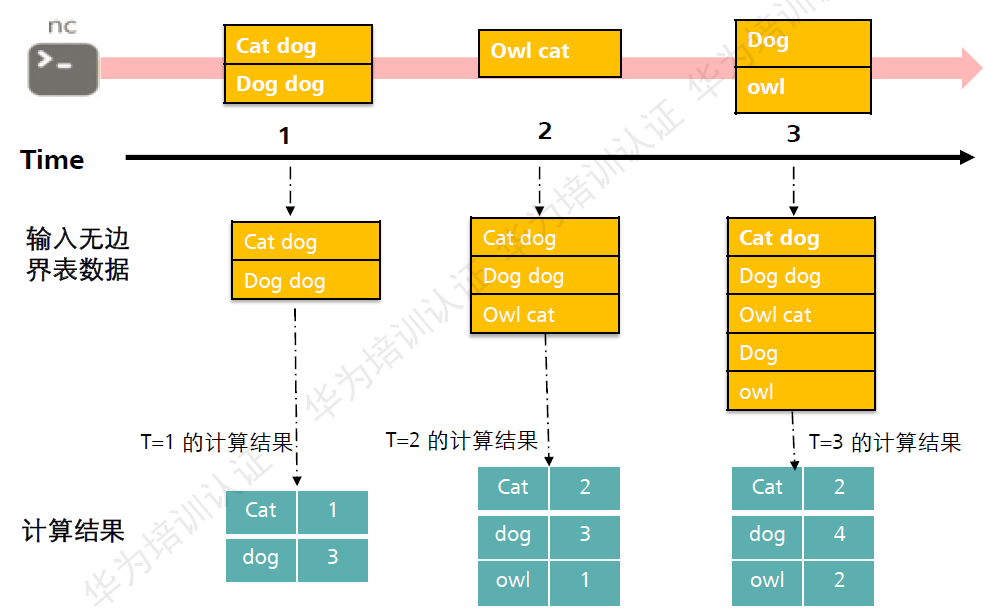
每一次计算后将结果更新到数据集中。
Spark Streaming
概述:
Spark Streaming是Spark核心API的一个扩展,一个实时计算框架。具有可扩展性、高吞吐量、可容错性等特定。

Spark Streaming微批处理:
Spark Streaming计算基于DStream,将流式计算分解成一系列短小的批处理作业。Spark引擎将数据生成最终结果数据。

使用DStream从Kafka和HDFS等源获取连续的数据流,DStreams由一系列连续的RDD组成,每个RDD包含确定时间间隔的数据,任何对DStreams的操作都转换成对RDD的操作。
Spark Streaming容错机制:
Spark Streaming本质仍是基于RDD计算,当RDD的某些partiton丢失,可以通过RDD的血统机制重新恢复丢失的RDD。
Spark的部署和应用方式
Spark三种部署方式:
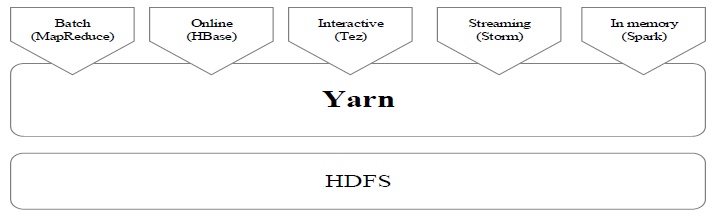
Spark支持三种不同类型的部署方式,包括:
- Standalone(类似于MapReduce1.0,slot为资源分配单位)
- Spark on Mesos(和Spark有血缘关系,更好支持Mesos)
- Spark on YARN
从Hadoop+Storm架构转向Spark架构:
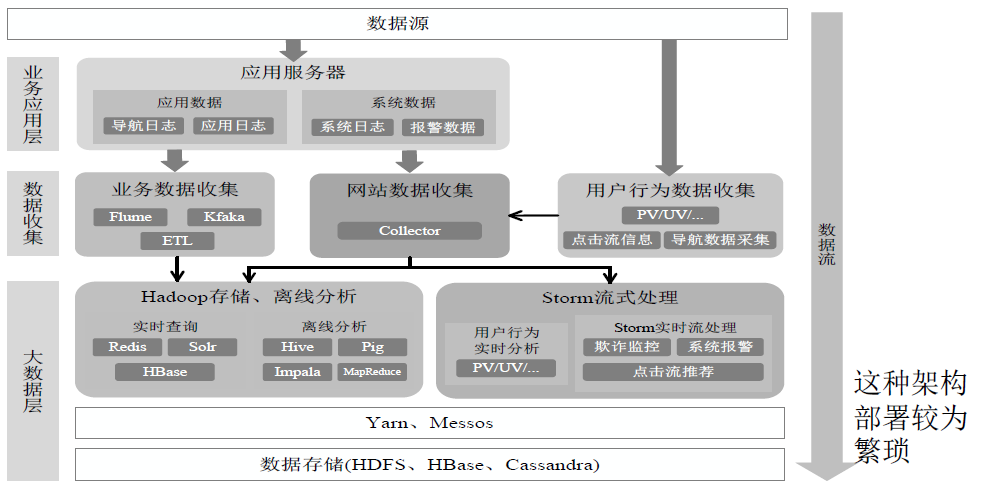
用Spark架构具有如下优点:
实现一键式安装和配置、线程级别的任务监控和告警.降低硬件集群、软件维护、任务监控和应用开发的难度。
便于做成统一的硬件、计算平台资源池.
需要说明的是,Spark Streaming无法实现毫秒级的流计算,因此,对于需要毫秒级实时响应的企业应用而言,仍然需要采用流计算框架(如Storm).
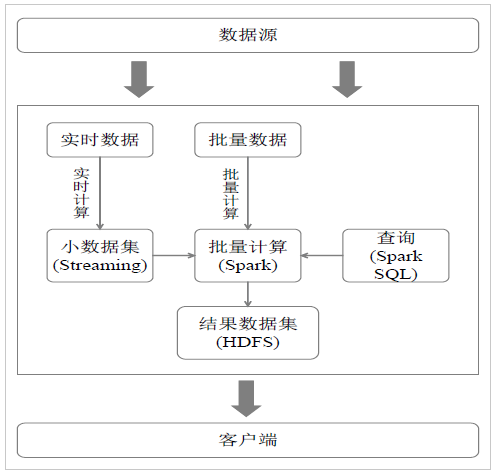
Hadoop和Spark的统一部署:
由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的,比如,Storm。
现有的Hadoop组件开发的应用,完全转移到Spark上需要一定的成本,不同的计算框架统一运行在YARN中,可以带来如下好处:
- 计算资源按需伸缩
- 不用负载应用混搭,集群利用率高
- 共享底层存储,避免数据跨集群迁移
以上内容为听华为大数据培训课程和大学MOOC上厦门大学 林子雨的《大数据技术原理与应用》课程而整理的笔记。
大数据技术原理与应用: https://www.icourse163.org/course/XMU-1002335004

