Flink简介
Flink概述:

Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并发化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
Flink与Storm类似,属于事件驱动型实时流系统。
Flink特点:
- Streaming-first、流处理引擎。
- Fault-tolerant,容错,可靠性,checkpoint。
- Scalable,可扩展性,1000节点以上。
- Performance,性能,高吞吐量, 低延迟。
Flink关键特性:
- 低延时:提供ms级时延的处理能力。
- Exactly Once:提供异步快照机制,保证所有数据真正处理一次。
- HA:JobManager支持主备模式,保证无单点故障。
- 水平扩展能力:TaskManager支持手动水平扩展。
Hadoop兼容性:
- Flink能够支持Yarn,能够从HDFS和HBase中获取数据。
- 能够使用所有的Hadoop的格式化输入和输出。
- 能够使用Hadoop原有的Mappers和Reducers,并且能与FLink的操作混合使用。
- 能够更快的运行Hadoop作业。
Flink应用场景:
Flink最适合的应用场景是低延时的数据处理场景:高并发处理数据,实验毫秒级,且兼具可靠性。
典型应用场景有:
- 互联网金融业务。
- 点击流日志处理。
- 舆情监控。
流式计算框架的性能对比:
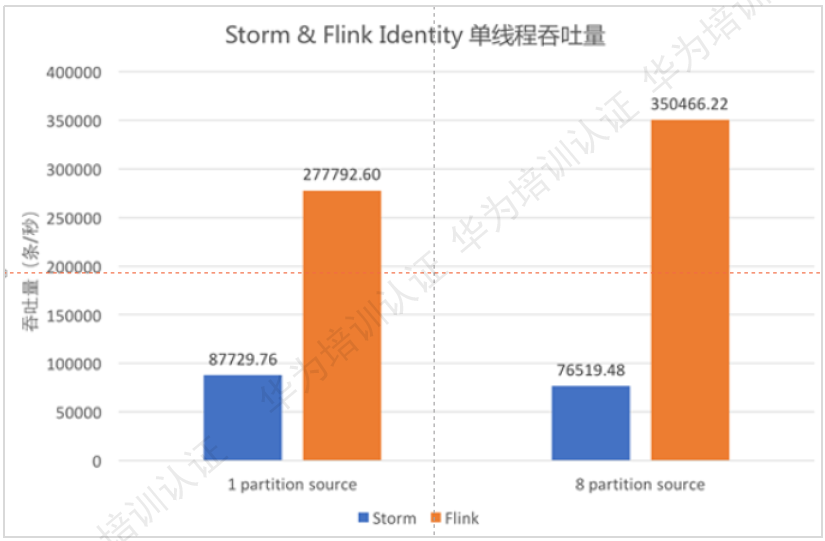
通过对比,可以看出Flink流计算框架比Storm的性能高的多。
Flink在FusionInsight产品中的位置:
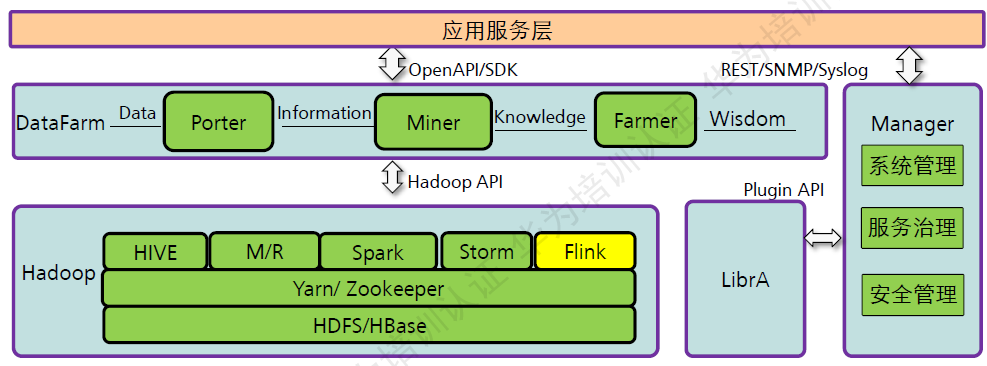
FusionInsight HD提供大数处理环境,基于社交开源软件增强,按照场景选择业界最佳实践。
FLink是批处理和流处理结合的统计计算框架,用于高并发pipeline处理数据,实验毫秒级的场景响应,且兼具可靠性。
在FusionInsight HD集群中,Flink主要组以下组件进行交互:
- HDFS:Flink在HDFS文件系统中读写数据(必选)。
- YARN:Flink任务的运行以来Yarn来进行资源的调度管理(必选)。
- Zookeeper:FLink的checkpoint的实现依赖Zookeeper。(必选)
- Kafka:Flink可以接收Kafka发送的数据流(可选)。
Flink原理与技术架构
Flink架构:
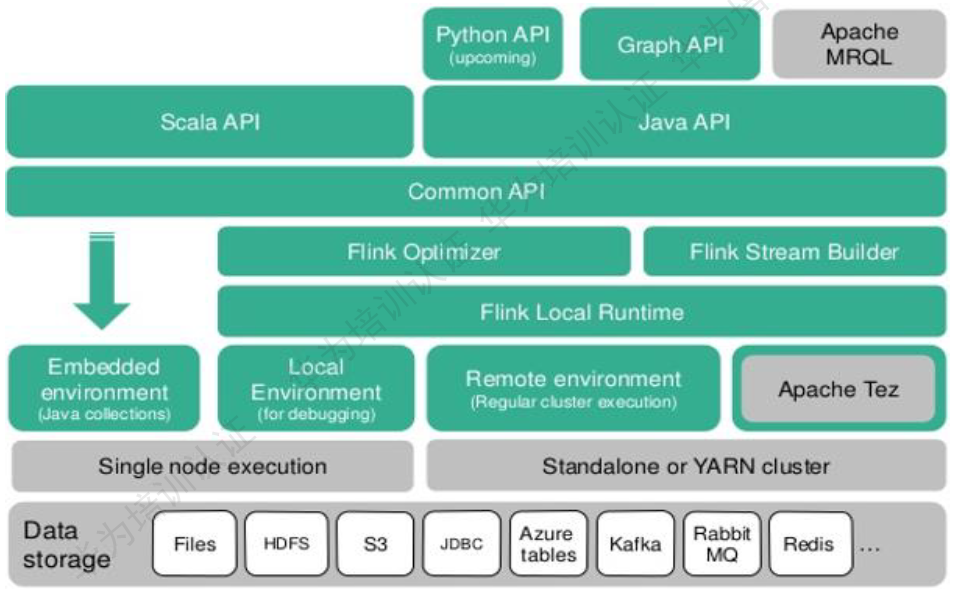
##Flink技术栈:
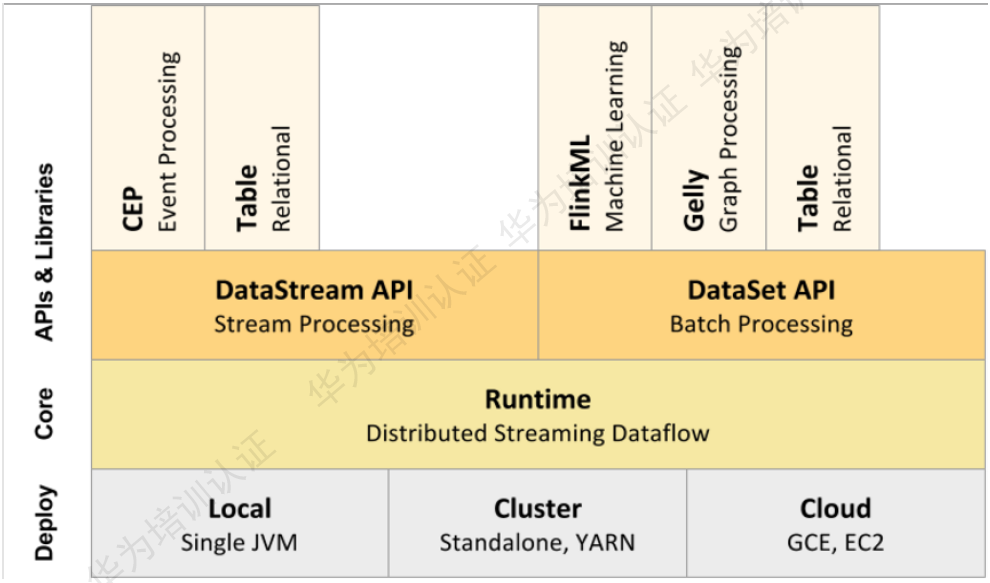
API:DataStream API是用于流处理的接口。
DataSet API是用于批处理的接口。它们都会使用单独编译的处理方式。
- Core:Flink的Core叫做Runtime,是Flink流处理和批处理时共用的一个引擎。Runtime以
- Deploy(部署方式):在最底层,Flink提供了三种部署模式。分别为Local,Cluster,Cloud。
Flink核心概念–DataStream:
DataStream:FLink用类DataStream来表示程序中的流式数据、用户可以认为它们是含有重复数据的不可修改的集合(Collection),DataStaram中元素的数据时无限的。
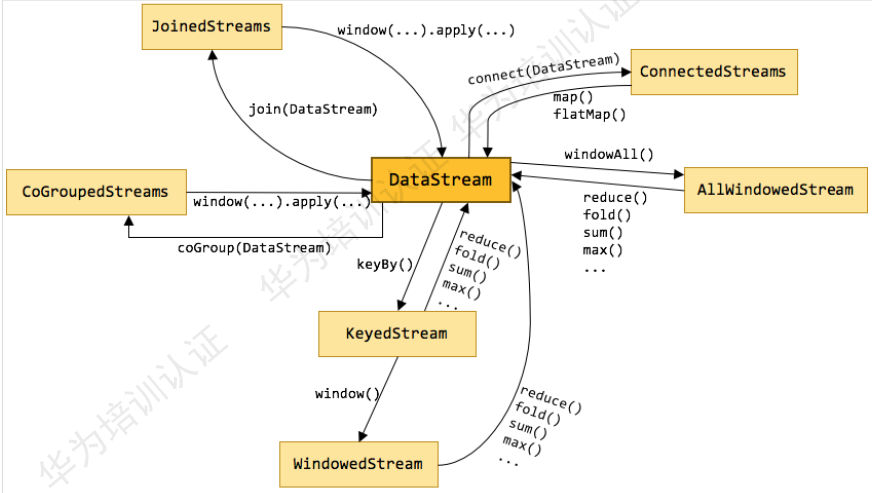

- Data Source:流数据源的接入,支持HDFS文件,Kafka,文本数据等。
- Transformations:流数据转换。
- Data sink:数据输出,支持HDFS,Kafka,文本等。
Flink数据源:
批处理:
- Files:HDFS,Local file system,MapReduce file system,Text,csv等。
- JDBC
- HBase
- Collections
流处理:
- Files
- Socket streams
- Kafka
- Flume
- Collections
- RabbitMQ
DataStream Transformation:
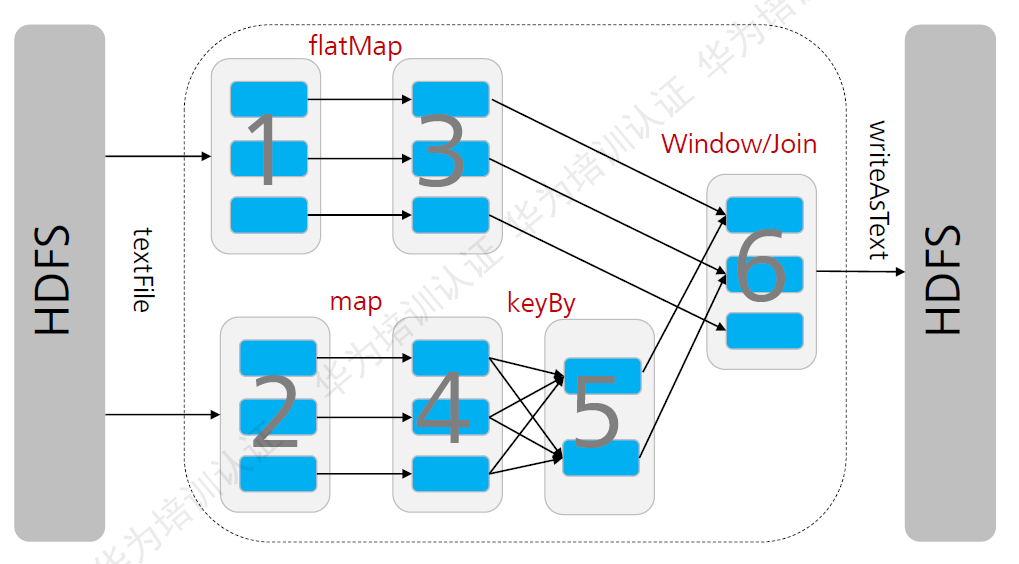
常用的Transformation有:map(), flatMap(), filter(), keyBy(), partition(), rebalance(), shuffle(), broadcast(), project()等。
Flink运行流程:
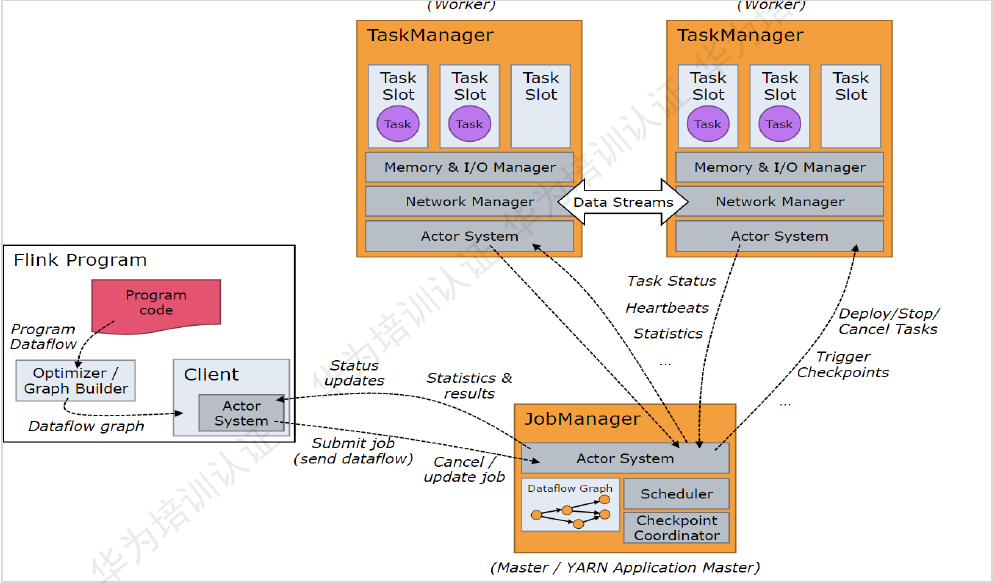
关键角色概念:
- Client:需求提出方,负责提交需求(应用),构造流图。
- JobManager:负责应用的资源管理,根据应用的需求,想资源管理部门(ResourceManager)申请资源。
- Yarn的ResourceManager:资源管理部门,负责整个集群的资源统一调度和分配。
- TaskManager:负责实际计算工资,一个应用会拆给多个TaskManager来进行计算。
- TaskSlot:任务槽,类似于Yarn当中的Container,用于资源的封装。但是在FLink中,taskSlot只负责封装内存的资源,不包含CPU的资源。每一个TaskManager中会包含3个TaskSlot,所以每一个TaskManager中最多能并发执行的任务是可控的,最多3个。TaskSlot有独占的内存资源,在一个TaskManager中可以运行不同的任务。
- Task:TsakSlot当中的Task就是任务执行的具体单元。
Flink on YARN:
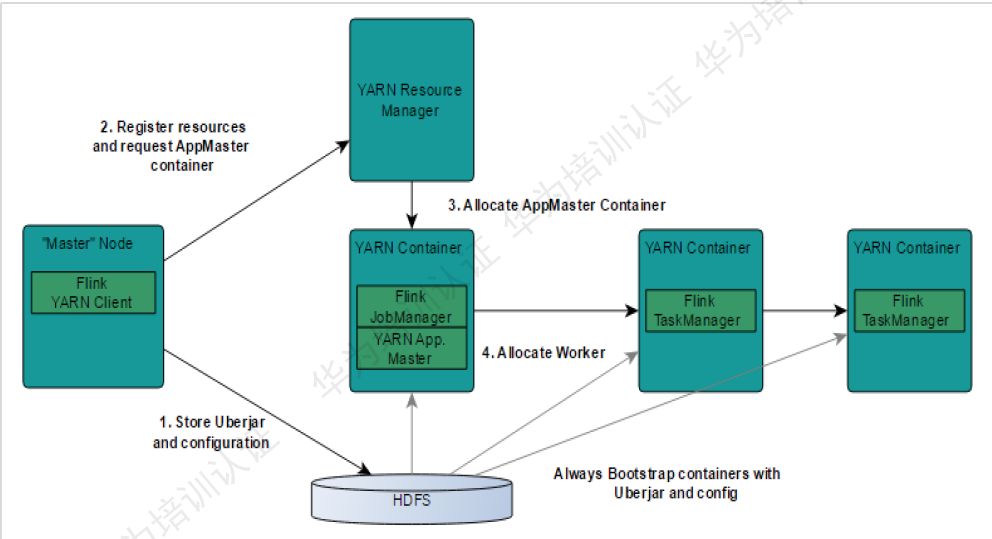
- 首先Flink Yarn Client会检验系统是否有足够的资源来启动YARN集群,如果资源足够,它就会将Jar包和配置文件上传到HDFS。
- Flink YARN CLient首先与Yarn ResourceManager进行通信,申请启动applicationMaster,在FLink Yarn的集群中,ApplicationMaster与Flink JobManager被封装在同一个container中。
- ApplicationMaster在启动的过程中,会和Yarn的ResourceManager进行交互,向ResourceManager申请所需要的TaskManager Container。当ApplicationMaster申请到TaskManager Container以后,它会在所对应的NodeManager节点上启动TaskManager进程。
- 由于ApplicationMaster和Flink JobManager是封装在同一个Container中的,所以ApplicationMaster会将JobManager的IPC地址,通过HDFS共享的方式通知到各个TaskManager上。TaskManager启动成功以后,就会向JobManager进行注册。
- 当所有的TaskManager都向JobManager注册成功以后,Flink基于Yarn的集群就启动成功了。Flink Yarn Client就可以提交FLink job到Flink JobManager上,然后进程后面的映射、调度、计算等处理。
Flink原理:
用户实现的Flink程序是由Stream数据和Transformation算子组成。
Stream是一个中间结果数据,而Transformation是算子,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
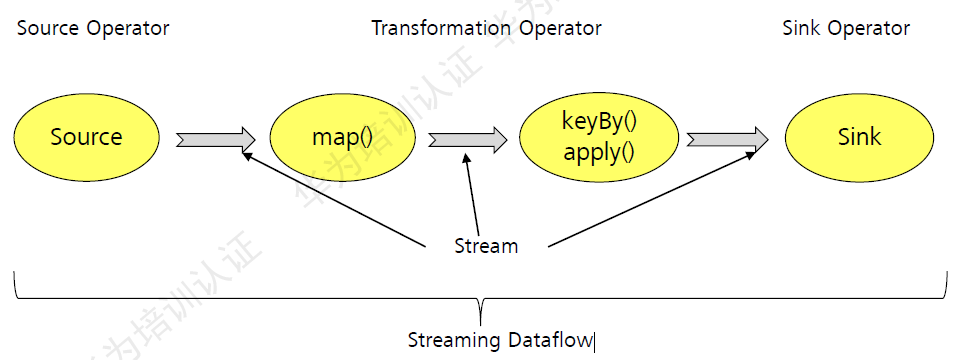
Flink程序在执行的时候,会被映射成一个Streaming Dataflow,一个Streaming Dataflow是由一组Stream和Transformation Operator组成的。在启动时从一个或多个Source Operator开始,结束与一个或多个Sink Operator。
Source操作符载入数据,通过map(), keyBy(), apply()等Transformation操作符处理stream。数据处理完成后,调用sink写入相关存储系统,如HDFS、HBase、Kafka等。
###Flink并行数据流:
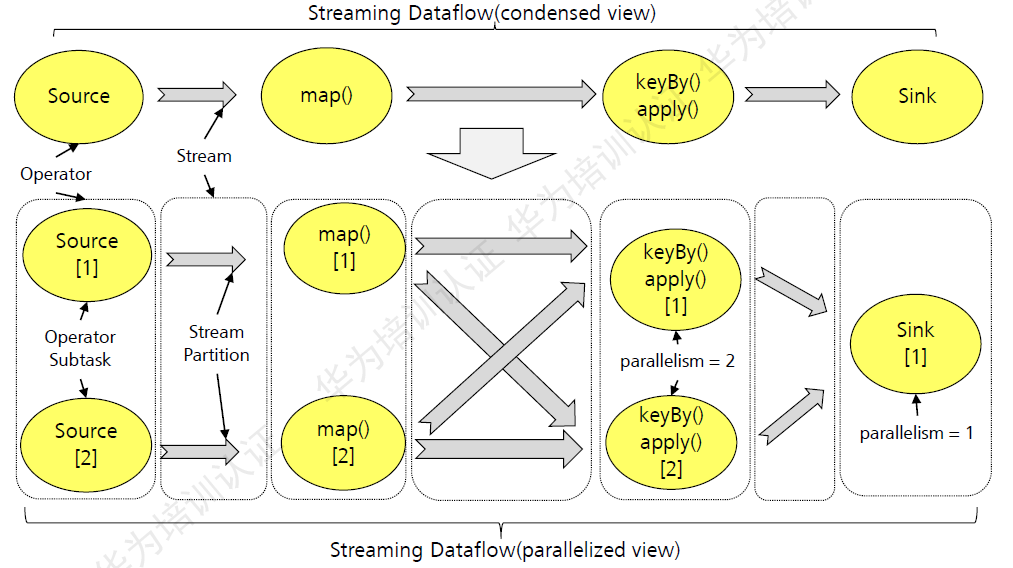
一个Stream可以被分成多个Stream的分区,也就是Stream Partition。一个Operator也可以被分为多个Operator Subtask。如上图中,Source被分成Source1和Source2,它们分别为Source的Operator Subtask。每一个Operator Subtask都是在不同的线程当中独立执行的。一个Operator的并行度,就等于Operator Subtask的个数。上图Source的并行度为2。而一个Stream的并行度就等于它生成的Operator的并行度。
数据在两个operator之间传递的时候有两种模式:
- One to One模式:两个operator用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的Source1到Map1,它就保留的Source的分区特性,以及分区元素处理的有序性。
- Redistributing 模式:这种模式会改变数据的分区数;每个一个operator subtask会根据选择transformation把数据发送到不同的目标subtasks,比如keyBy()会通过hashcode重新分区,broadcast()和rebalance()方法会随机重新分区;
###Flink操作符链:
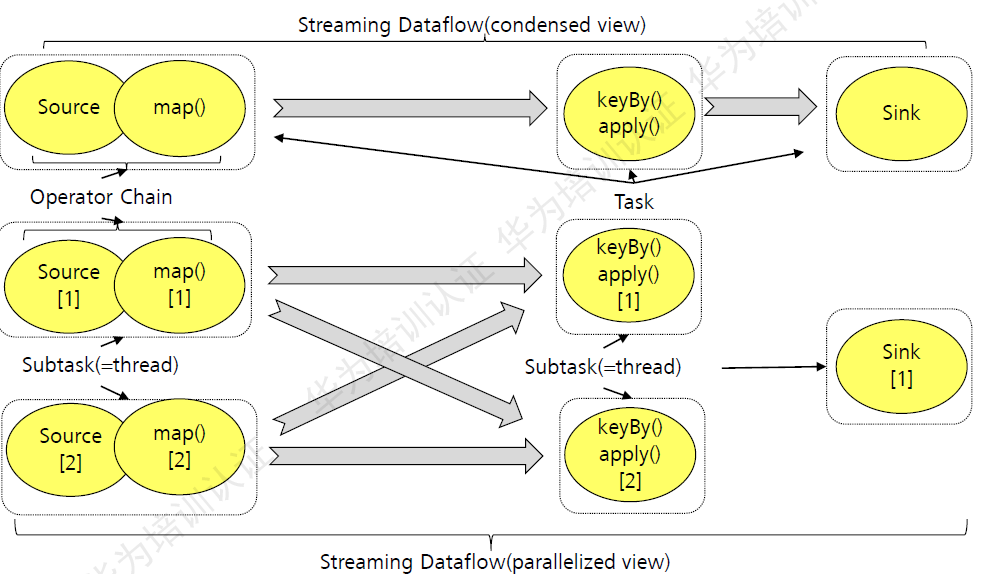
Flink内部有一个优化的功能,它会根据上下游算子的紧密程度来进行优化,紧密程度高的算子可以把它优化成一个大的Operator。如图中的Source和Map紧密程度很高,就可以优化成一个Operator Chain。实际上就是一个执行链,每个执行链都会在TaskManager中一个独立的线程汇总执行。Operator Chain实际上就是一个Operator,keyBy也是一个Operator,sink也是一个Operator,图的上半部分都是通过Stream连接,每个Operator都在一个独立的Task中运行。下半部分是上半部分的一个并行版本,对每一个Task都并行为多个Subtask。
Flink窗口:
Flink支持基于时间窗口操作,也支持基于数据的窗口操作:
- 按分割标准划分:timeWindow、countWindow。
- 按窗口行为划分:Tumbling Window, Sliding Window、自定义窗口。
Flink常用窗口类型—时间和计数窗口:
TimeWindow:时间窗口,按固定的时间划分的窗口。
CountWindow:事件窗口,窗口是以数据驱动的,比如每经过100个元素,就把这100个元素归结到一个事件窗口当中。

Flink常用窗口类型—滚动窗口:
Tumbing Windows:滚动窗口,窗口之间时间点不重叠。它是按照固定的时间,或固定的事件个数划分的,分别可以叫做滚动时间窗口和滚动事件窗口。
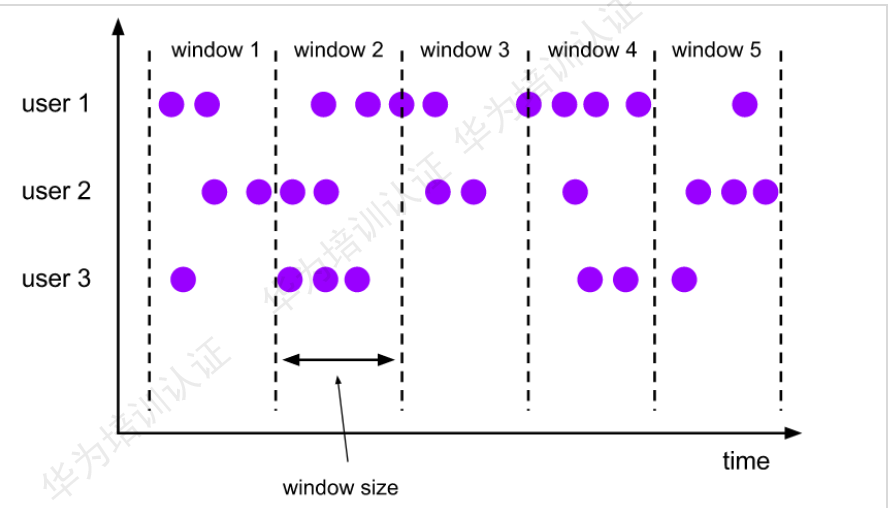
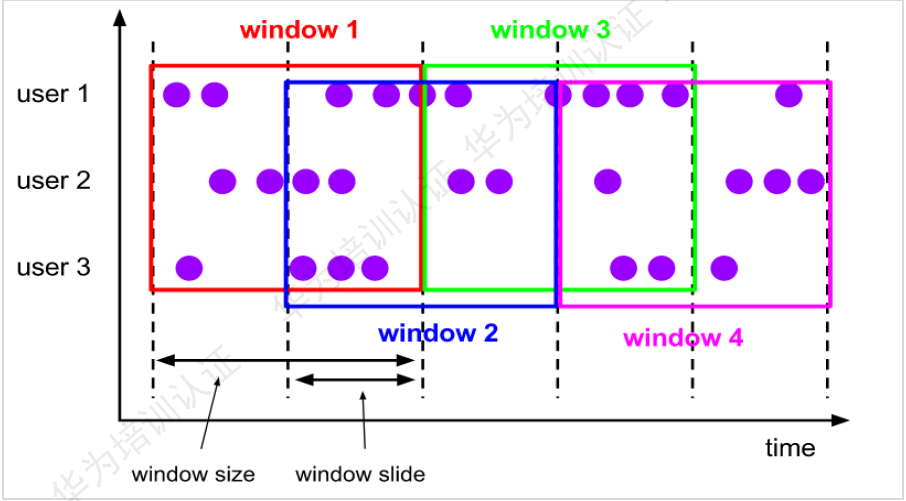
Flink常用窗口类型—滑动窗口:
Sliding Windows:滑动窗口,窗口之间时间点存在重叠。对于某些应用,它们需要的时间是不间断的,需要平滑的进行窗口聚合。例如,可以每30s记算一次最近1分钟用户所购买的商品数量的总数,这个就是时间滑动窗口;或者每10个客户点击购买,然后就计算一下最近100个客户购买的商品的总和,这个就是事件滑动窗口。
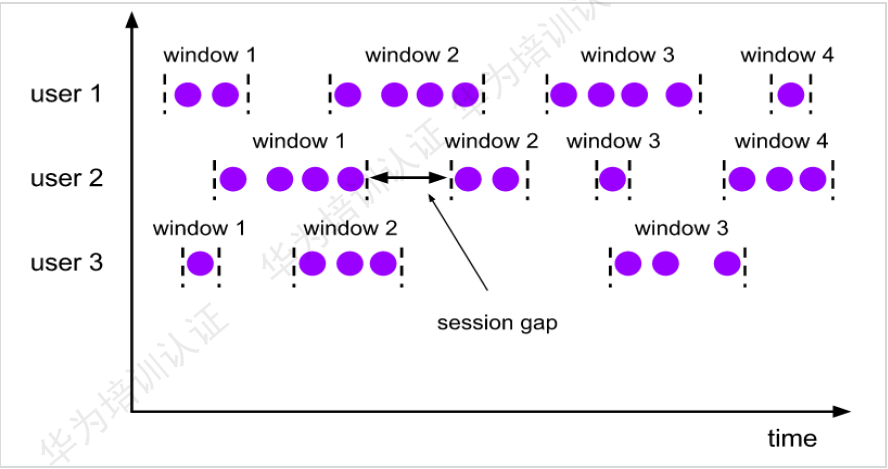
Flink常用窗口类型—会话窗口:
Session Windows:会话窗口,经过一段设置时间无数据认为窗口完成。
Flink高级特性
Flink容错功能:
- ckeckpoint机制是FLink运行过程中容错的重要手段。
- checkpoint机制不断绘制流应用的快照,流应用的状态快照被保存在配置的位置(如:JobManager的内存里,或者HDFS上)。
- Flink分布式快照机制的核心是barriers,这些barriers周期性插入到数据流中,并作为数据流的一部分随之流动。
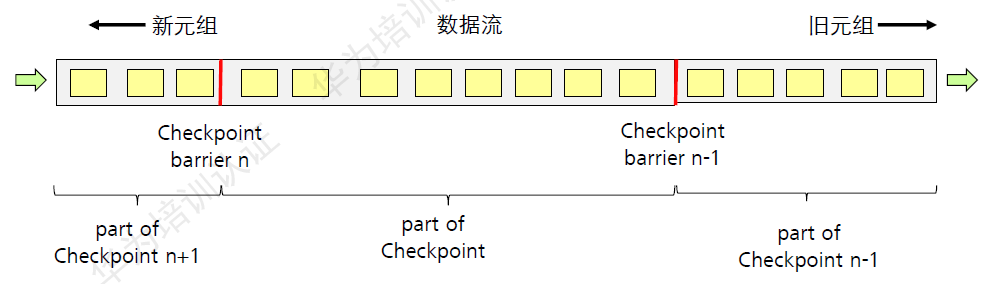
Checkpoint机制是Flink可靠运行的基石,可以保证Flink集群在某个算子因为某些原因(如异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。
该机制可以保证应用在运行过程中出现失败时,应用的所以有状态能够从某一个检测点恢复,保证数据仅被处理一次(Exactly Once)。另外,也可以选择至少处理一次(at least once)。
Checkpoint机制具体执行过程:
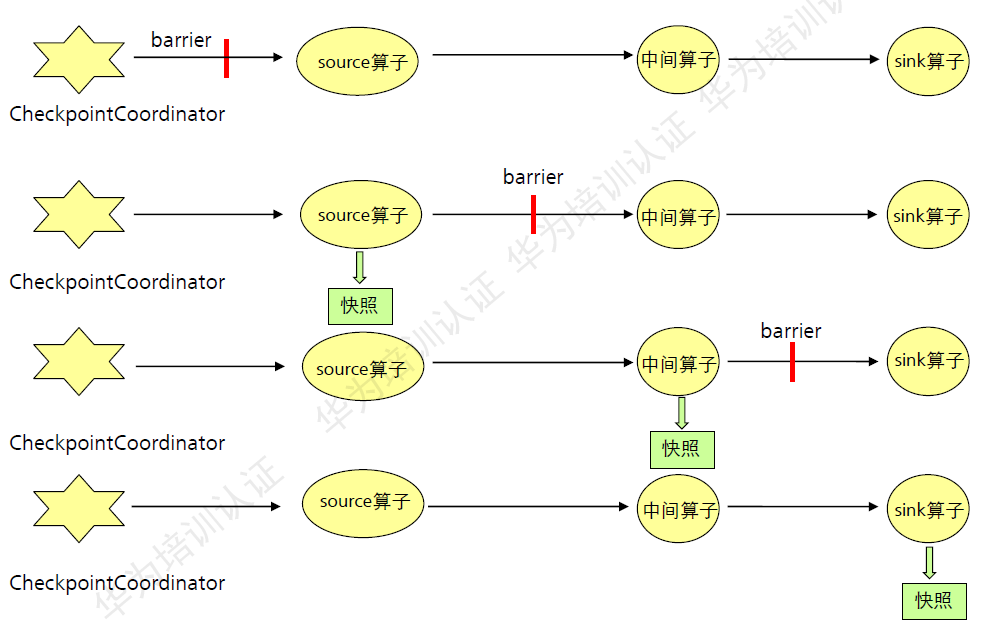
每个需要checkpoint的应用,它在启动的时候,Flink的JobManager就会为它创建一个checkpointCoordinator。checkpointCoordinator它全权负责本应用的快照的制作,用户可以通过checkpointCoordinator中的setCheckpointInterval接口设置checkpoint的周期。
- Checkpoint机制的第一步,就是CheckpointCoordinator周期性的向该流应用,所有的source算子发送barrier。
- 第二步,Source算子接收到一个barrier后,便暂停处理数据,将当前的状态制作成快照,并保存到指定的持久化存储中,最后它再向CheckpointCoordinator报告自己的快照制作情况。同时向自身下游所有算子广播该barrier。然后恢复该算子的数据处理工作。
- 下游的算子接收到barrier后,也会暂停自的数据处理过程,同2过程。
- 最后CheckpointCoordinator会确认它接收到的报告,如果收到本周期的所有算子的快照就认为快照制作成功,否则失败。
多Source源的Checkpoint机制:
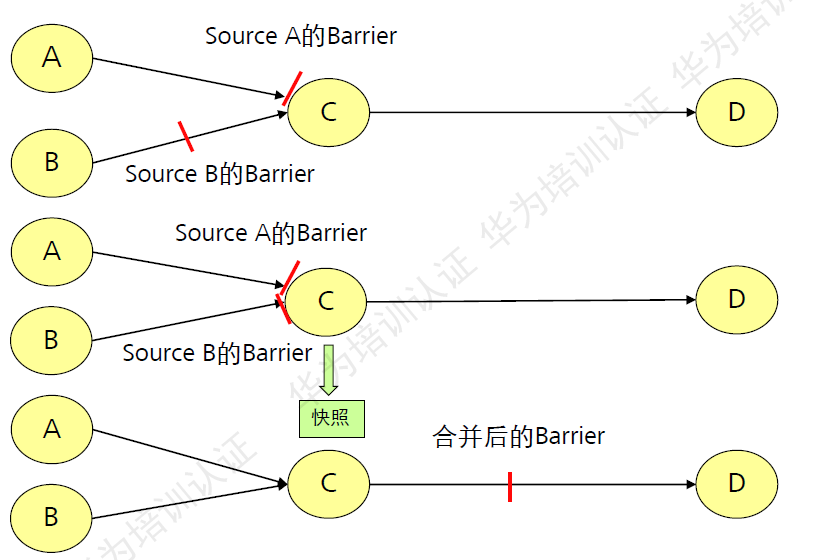
当一个算子上游有多个来源时,它会将首先接收到barrier端阻塞掉,等待其他输入端的barrier,只有当接收到所有输入端的barrier时,该算子才会开始合并barrier执行制作快照过程,并将合并后的barrier广播到下游算子。
以上内容为听华为大数据培训课程和大学MOOC上厦门大学 林子雨的《大数据技术原理与应用》课程而整理的笔记。
大数据技术原理与应用: https://www.icourse163.org/course/XMU-1002335004

